
How Index States Indicate Crawl Priority
How reverse indexing in GSC can reveal the crawl priority of your pages in Googlebot.

Indexing Insight helps you monitor Google indexing for large-scale websites with 100,000 to 1 million pages. Check out a demo of the tool below 👇.
Google Search Console is misreporting ‘URL is unknown to Google’.
Every SEO team uses the coverage states in Google Search Console to debug crawling and indexing issues in Google Search.
However, Google can actively reverse index coverage states.
In this newsletter, I'll explain how index coverage states can be reversed. And how these states can tell us the level of crawl priority in Google’s system by mapping them to Googlebot’s crawl, render and index process.
I'll explain reverse indexing coverage states using examples from Indexing Insight.
Let's dive in.
Update: I’ve updated the article due to comments from Gary Illye.
🚦 What is the coverage state?
Every page in the Search Console’s Page Indexing report has a coverage state.
The coverage state of a page is why a page is either indexed or not indexed (e.g. ‘crawled - currently not indexed’ and ‘submitted and indexed’).
You can see the coverage state in the Page Indexing report under the Reasons category…

…and view the coverage state in the URL Inspection report.

⌛ Tracking Historic Coverage States
The most fascinating thing about the page’s coverage state is that it’s constantly changing.
BUT you can’t usually detect these changes in Google Search Console because they don’t track historic changes in a page’s coverage state.
However, we can detect these changes with Indexing Insight.
For example, we track any change in the coverage state of page URLs being monitored and any changes in the canonical URL.
We also email users daily to update them on any changes we’ve found.
These emails are always interesting. You can see pages move between the different index coverage states.

Tracking changes over millions of URLs for our alpha testers led us to a surprising conclusion.
A page’s indexing coverage state can go backwards from being submitted and indexed to Google, telling you that the URL is “unknown”.
For example, a typical page usually goes through the following steps:
⬇️ ‘URL is unknown to Google’
⬇️ ‘Discovered - currently not indexed’
⬇️ ‘Crawled - currently not indexed’
✅ ‘Submitted and indexed’
But over time, the same page coverage state can go backwards from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Discovered - currently not indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘URL is unknown to Google’
Let’s look at some examples to understand page coverage states going backwards in the wild.
Examples of Coverage States Going Backward
Below are 3 examples of a page’s coverage status reversing.
Example #1 - The SEO Sprint
The first example is from The SEO Sprint.
The current coverage state in the URL Inspection tool is ‘URL is unknown to Google’.

However, using the URL report in Indexing Insight, we can see that this particular URL was indexed and had its Google-selected canonical URL.

The Google-selected canonical change happened on the 15th of August, 2024. We even provide a link to a historic URL Inspection tool in Google Search Console.
The change in the canonical links indicates that Google dropped the data from its index.
When you open the link, you can see that historically, this page had a ‘crawled - currently not indexed’ coverage state.
If we look at the page's search performance, we can see that it had 18 impressions in March 2024. This indicates that this page was indexed and served in search results.

This page URL reverse index state went from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘URL is unknown to Google’
This page URL indexing state reversed, and the URL coverage state “went backwards”.
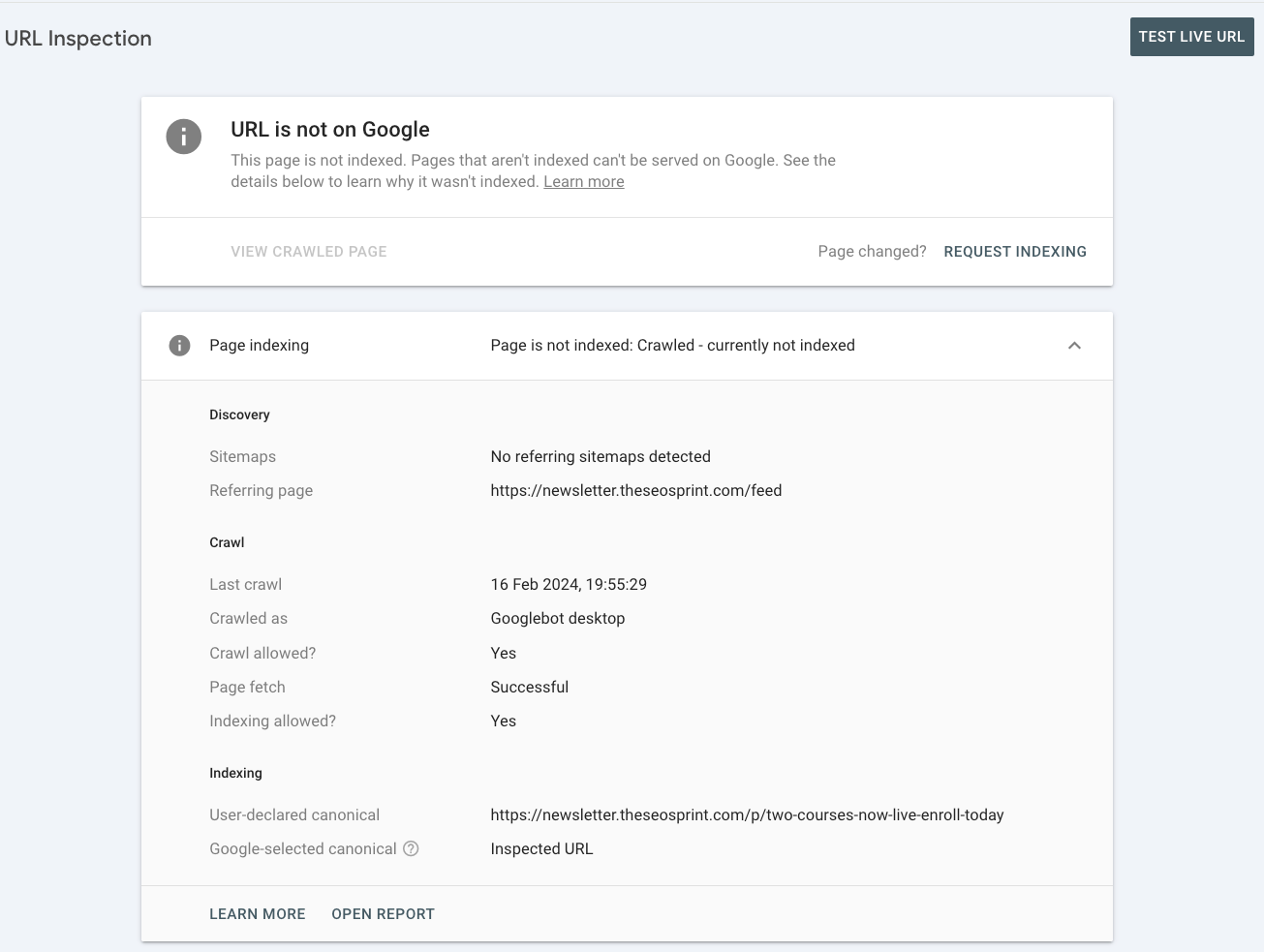
Example #2 - Programmatic SEO website
The second example is a programmatic SEO website.
In this example you can see the /cities/banbury/ URL is shown as URL is not on Google.

However, when checking the page's history in the URL report, we can see historic changes. The page was indexed (13th June 2024), and there were changes to the canonical URL (14th October 2024).

If we check the link to Search Console, we can see that the page has the coverage state of ‘crawled - currently not indexed’.

If we check the Search Performance of the page URL over the last 16 months we can see that this page was indexed. And it was served to users (which is why it has impressions).

Again, this page URL reverse index state went from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘URL is unknown to Google’ (current state in the URL Inspection tool)
Like the previous example, this page's URL indexing state reversed, and the URL coverage state “went backwards”.
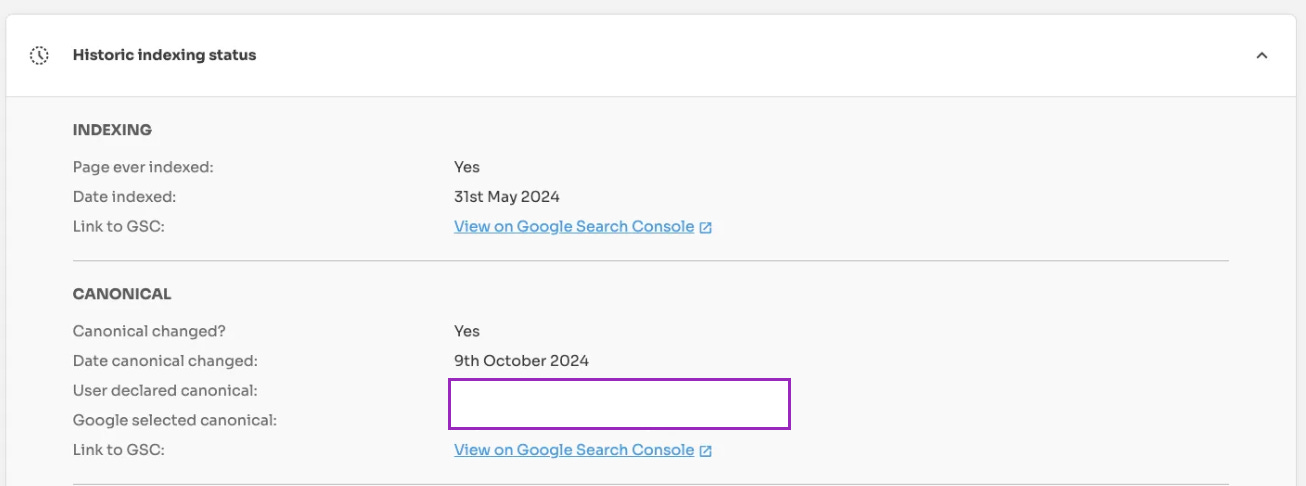
Example #3 - Niche Website
The final example is a niche cricket website.
If we input the page /players/niaz-khan/ into the URL Inspection tool, the current coverage state is ‘Discovered - currently not indexed’.

However, using Indexing Insights, we track any changes in a page's index state. As you can see, this particular URL was indexed on May 31st, 2024, and the canonical URL changed on October 9th, 2024.

If we open the historic URL Inspection report for when the canonical URL changed (9th October 2024), this page will have a ‘crawled - currently not indexed’ coverage state.

Finally, if we look at the performance over the last 16 months, we can see that the page has had impressions and clicks.
This indicates that Google indexed this page and showed it in its search results.

To recap, this cricket niche website page URL index state reversed and went from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘Discovered - currently not indexed’ (current state in the URL Inspection tool)
Like the other examples this page URL indexing state reversed, and the URL coverage state “went backwards”.
❓ Why are index coverage states reversing?
A page’s Indexing state can change based on historical data about the page.
Google recently published a video Help! Google Search isn’t indexing my pages on 20 Aug 2024. It’s a great video from Martin Splitt, and I recommend watching it.
The video focuses on the ‘Discovered - currently not indexed’ state in Search Console.
In the video, Martin explains that one of the most common reasons pages are in the ‘Discovered - currently not indexed’ category is that they have been actively removed from its index.
To quote the video:
“The other far more common reason for pages staying in "Discovered-- currently not indexed" is quality, though. When Google Search notices a pattern of low-quality or thin content on pages, they might be removed from the index and might stay in Discovered.”
- Martin Splitt, Help! Google Search isn’t indexing my pages, 20 Aug 2024
This confirms the ‘crawled - previously indexed’ behaviour we’ve seen in Indexing Insight.
It also confirms Google actively removes indexed content from its index AND when it is removed the coverage state changes.
But how do other coverage states work in Google’s crawling and indexing system?
That is what I set out to figure out.
⚙️ Googlebot System vs Coverage States
There is a lot of literature to choose from to explain crawling and indexing.
However, rather than trying to map the coverage states to years of in-depth documentation. I think it’s better to map the index coverage states to a simple diagram widely used by the SEO industry.
Luckily, I didn’t have to do much digging. Martin Splitt provided a Crawl, Render and Index diagram in the Help! Google Search isn’t indexing my pages YouTube video:

Based on the reverse coverage state examples I’d seen (and just shown), this diagram gave me an idea.
So, I asked Martin on Linkedin if the indexing status in Google Search Console could be mapped to the simple process he presented (source).

Martin confirmed that this was an accurate mapping to his knowledge.

Gary Illyes also confirmed on LinkedIn that URLs move between index states as they collect signals over time.

The confirmation from Martin and Gary was the final piece of the puzzle. It helped develop a theory on how the index coverage states map to the crawling and indexing system.
It’s all about how Google’s system prioritises the URLs to be crawled.
Below is a simple diagram of the crawling and indexing system mapped to the index coverage states.

The diagram is based on Martin's confirmation on LinkedIn and the Crawl, Render, and Index diagram from the Understand the JavaScript SEO basics documentation.
As you can see, certain index coverage states reflect less of a priority for Google.
The less “importance” a page URL is allocated over time, the more it moves backwards through the crawling and indexing process. And the more the indexing coverage state changes over time.
Until it reaches, the ‘URL is unknown to Google’ indexing state.
A URL can be so forgetful that Google’s systems can forget it exists. And a previously crawled or indexed page with this state has zero crawl priority.
To quote Gary Illyes when I asked him about historically crawled and indexed pages with the ‘URL is unknown to Google’:
“Those have no priority; they are not known to Google (Search) so inherently they have no priority whatsoever. URLs move between states as we collect signals for them, and in this particular case the signals told a story that made our systems "forget" that URL exists.”
- Gary Illyes, Analyst at Google Search
💡 A page’s index coverage state can be reversed
Google is actively removing pages from being displayed in its search results.
When pages are removed from Google’s index, the index coverage state changes based on the URL's priority in the Googlebot web crawling process.
But any change isn’t static. The coverage state can reverse over time.

What is interesting is that pages can become less important to crawl.
The index coverage states like ‘Discovered - currently not indexed’ and ‘URL is Unknown to Google’ for historically indexed pages are strong indicators that Google actively finds these pages low-quality.
How often does reverse indexing occur?
It happens more often than you think.
For one alpha tester, 32% of their 1 million submitted URLs have experienced reverse indexing over the last 90 days.
They can see that historical URLs are slowly being removed from Google’s serving index. And as more time passes the state is changing to be moved to other indexing states…

…which reflects the crawl priority in Google’s crawling system.
They can see the slow increase of coverage states ‘discovered - currently not indexed’ as the number of ‘crawled - previously indexed’ declines.

They are also seeing an increase in ‘URL is unknown to Google’ as important URLs become less of a crawl priority to Googlebot.

They are watching Googlebots crawl system deprioritizing URLs to be crawled.
🕵️ How to detect reverse index coverage in GSC
The coverage states in the page indexing report indicate levels of crawl prioritisation.
SEO teams can use the Search Console index coverage report to identify which important pages they want to rank are being actively removed by Google.
How can you find out?
Filter on the important pages you want to rank in Google Search.
In Google Search Console, go to Page Indexing > All Submitted Pages. This will provide you with a clearer picture of the pages that you want to rank in Google Search.

Do you see ‘crawled - currently not indexed’ or ‘discovered - currently not indexed’?
Then, it’s highly likely your pages are experiencing reverse index coverage states.
If you find ‘crawled - currently not indexed’ or ‘discovered - currently not indexed’ with this filter, it means:
❌ Google is removing pages - These pages will be actively removed from Google’s search results due to the quality or popularity of your pages/website.
🕷️ Less of a crawl priority - Any pages under ‘discovered - currently not indexed’ also indicate that these URLs are less of a priority to crawl and rank in Google Search.
🚦 Pages need action - The pages in the ‘discovered - currently not indexed’ category might need urgent action before disappearing into ‘URL is Unknown to Google’.
If nearly all your pages submitted are in these two categories, then it's a strong indication that your website is less of a priority to crawl, index, and rank in Google.
📌 Summary
The coverage states of your pages in the Page Indexing report are not static.
In this newsletter, I’ve provided evidence that Google will actively remove pages from its search results. AND that the coverage states of your pages can go backwards.
This reverse in index coverage state indicates low crawl priority in Googlebot’s system.
If we map the index coverage states to Googlebot’s crawl, render and index process we can see that pages in the ‘URL is Unknown to Google’ and ‘discovered - currently not indexed’ are less of a priority to crawl.
This is a problem because crawl priority indicates a page's ability to rank in Google.
Hopefully, this newsletter has inspired you to look at your page indexing report with a new understanding. And identify which pages are less of a priority for Google to crawl and index.
If you have any questions, please leave them in the comments below 👇.
📊 What is Indexing Insight?
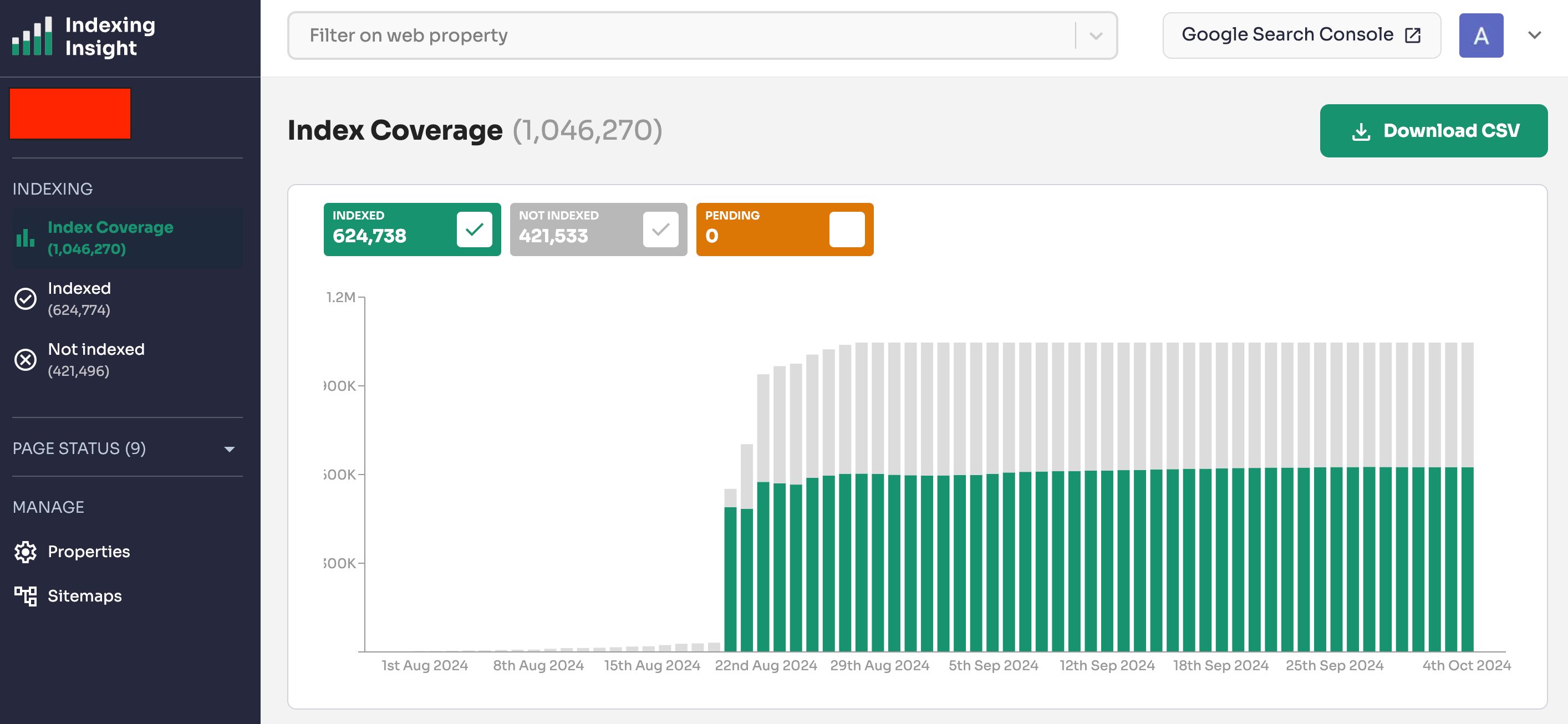
Indexing Insight is a tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
Awesome article, thank you 👍