Google Search Console is misreporting ‘URL is unknown to Google’.
The coverage state ‘URL is unknown to Google’ indicates to SEO teams that Google has never seen this page before.
However, this definition is misleading.
In this newsletter, I'll explain the current definition of ‘URL is unknown to Google’ and why it needs to change.
I'll explain why we need two definitions using examples from Indexing Insight data.
So, let's dive in.
Update 27/01/2025:: I updated the article based on Gary Illyes comments. It seems that Google can “forget” URLs as they purge low-value pages from their index over time.
🕷️ What is ‘URL is unknown to Google’?
‘URL is unknown to Google’ is a page indexing coverage state in Google’s Search Console.
If you do a Google search for ‘URL is unknown to Google’, many articles define this state as Google’s crawlers having never seen this URL before. Ever.
All of these definitions are just repeating the official definition from Google’s documentation:
“If the label is URL is unknown to Google, it means that Google hasn't seen that URL before, so you should request that the page be indexed. Indexing typically takes a few days.”
However, based on the data on Indexing Insights, this definition needs to change.
Update 27/01/2025: It seemsthat Googlebot’s systems can “forget” a URL that was previously crawled and indexed over time as they gather more signals. So the definition is strictly correct.
To Googlebot they have not seen that URL before because it was so forgettable.
❓ Why does the definition need to change?
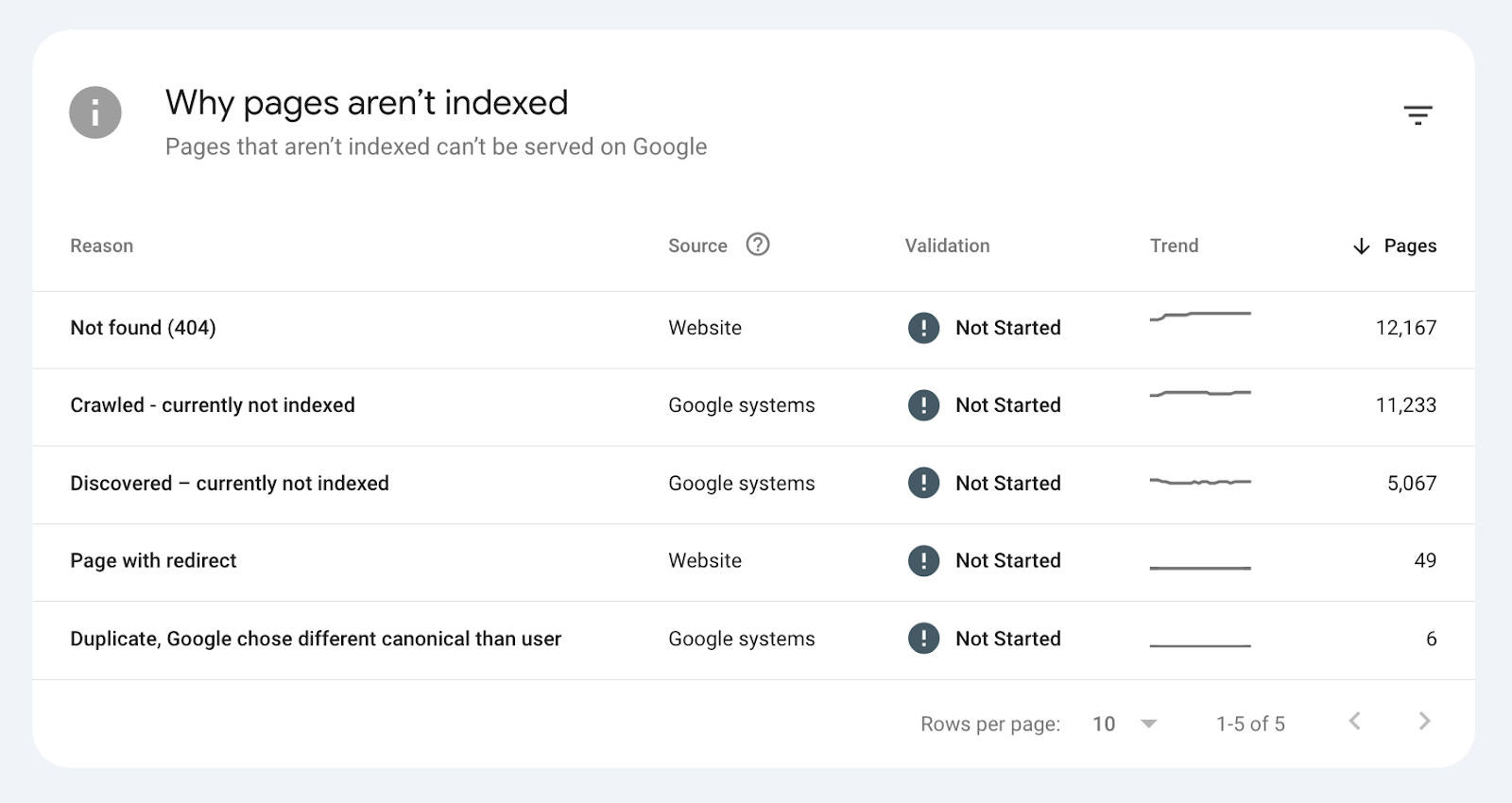
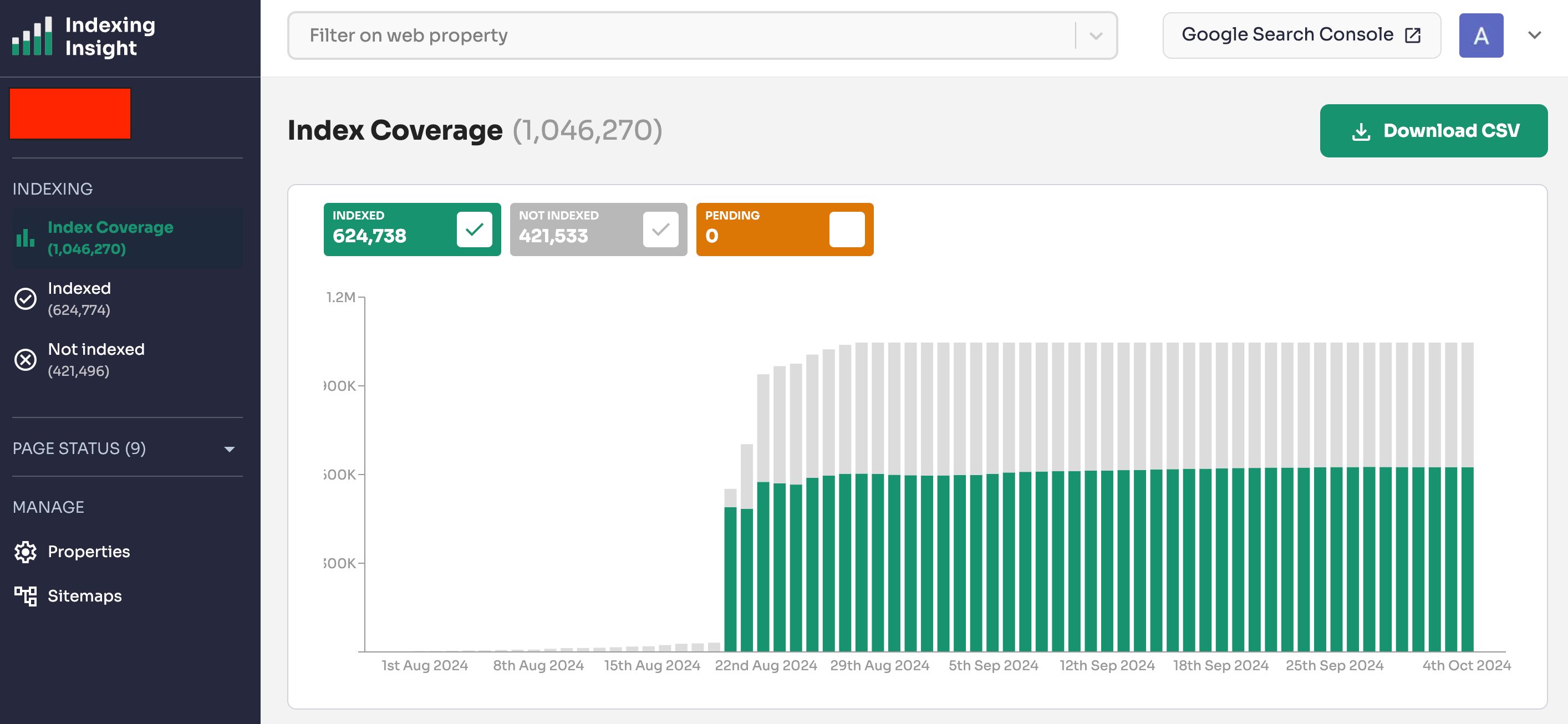
Data from Indexing Insight shows that ‘URL is unknown to Google’ definition is inaccurate.
Based on our data, Google has seen pages labelled ‘URL is unknown to Google’. In some cases, Google has historically crawled and indexed these URLs.
The problem is that indexing data in the URL Inspection Tool isn’t giving you all the data.
↔️ Index coverage states change (constantly)
It’s important to understand that coverage states for pages are constantly changing.
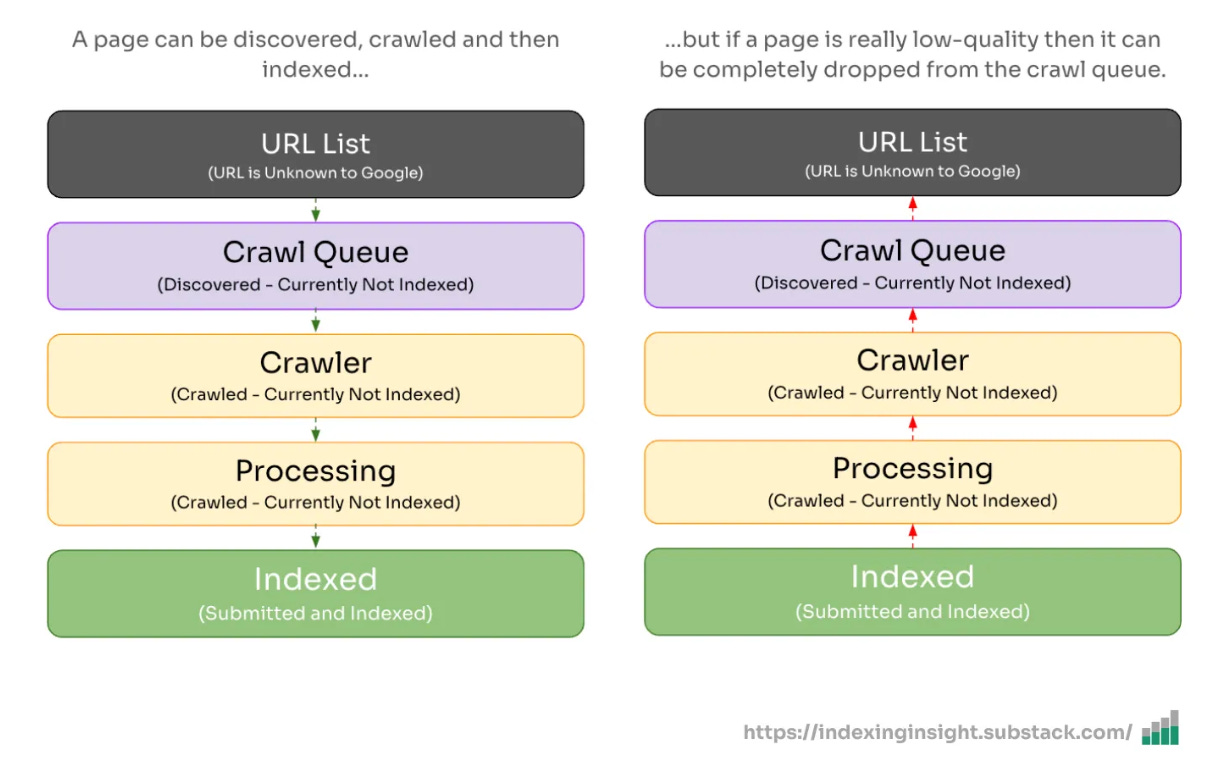
Active removal - Google actively removes URLs from being displayed in its search results (Submitted and indexed > Crawled - currently not indexed)
Index States Change - When URLs are removed from being served in Google Search results, their coverage state changes based on their crawl priority in Googlebot.
Reversal - But any change isn’t static. The coverage state can reverse over time.
The ‘URL is unknown to Google’ ends this process.
A URL with an “unknown” coverage state indicates zero crawl priority in Googlebot’s crawling process. You want to avoid this state.
Let’s look at examples of indexed URLs moving to ‘URL is unknown to Google’.
🎨 Examples of “unknown” URLs to Google
Let’s look at a few examples of URLs marked as ‘URL is unknown to Google’.
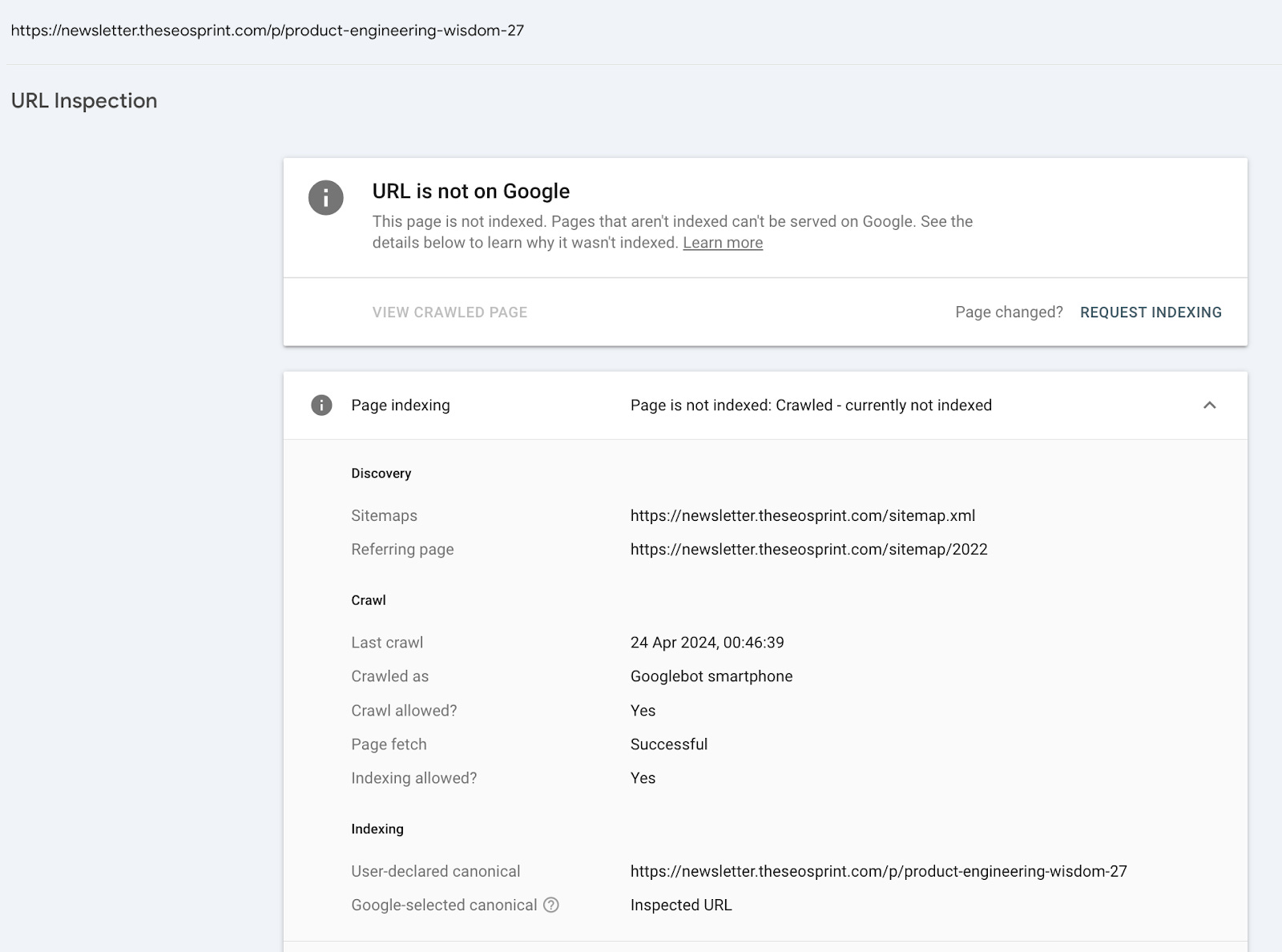
Example #1 - The SEO Sprint newsletter
The first example is from The SEO Sprint website.
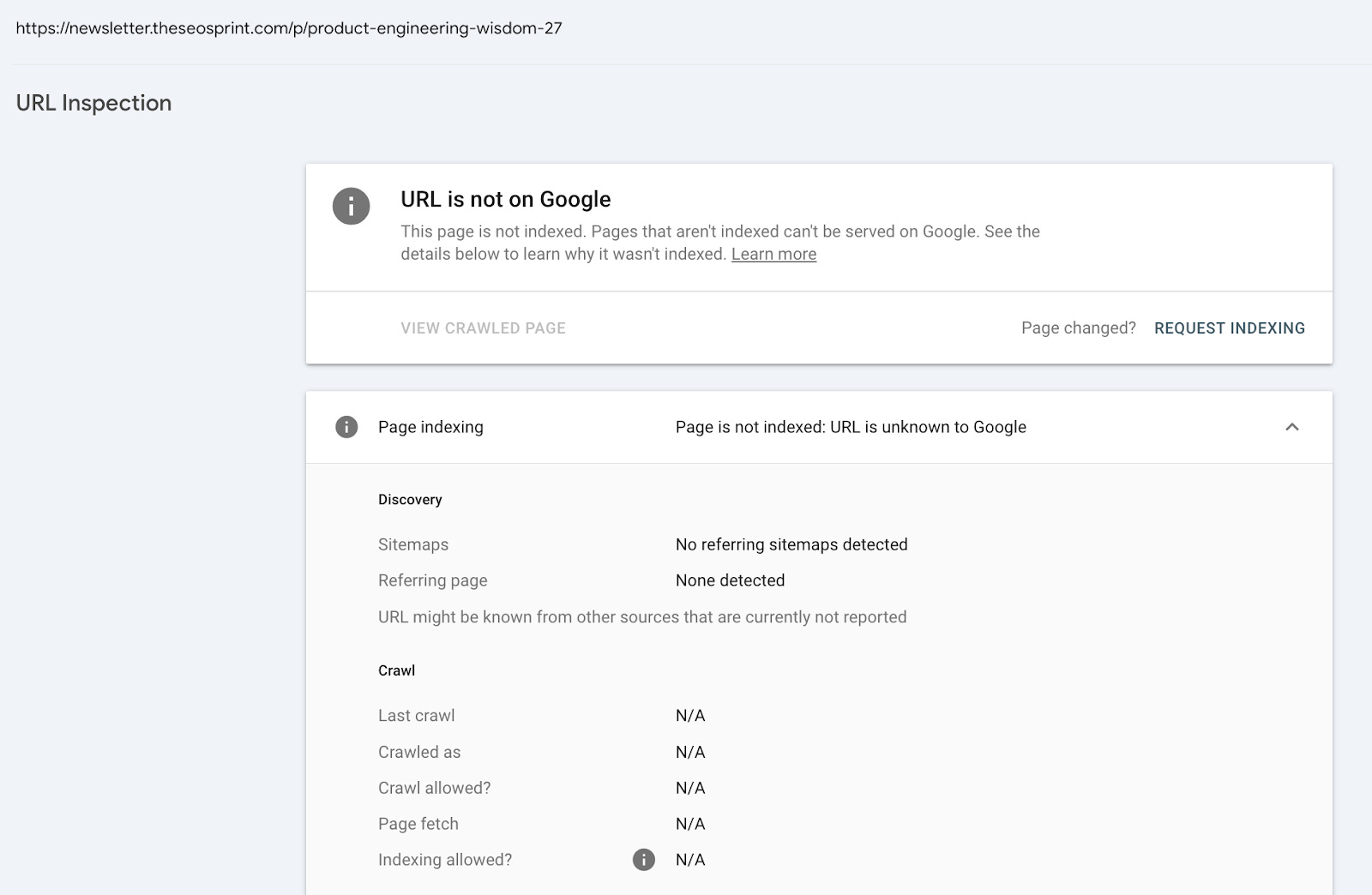
If we test the following URL /p/product-engineering-wisdom-27 in the URL Inspection Too, we can see that it shows the coverage state ‘URL us unknown to Google’.
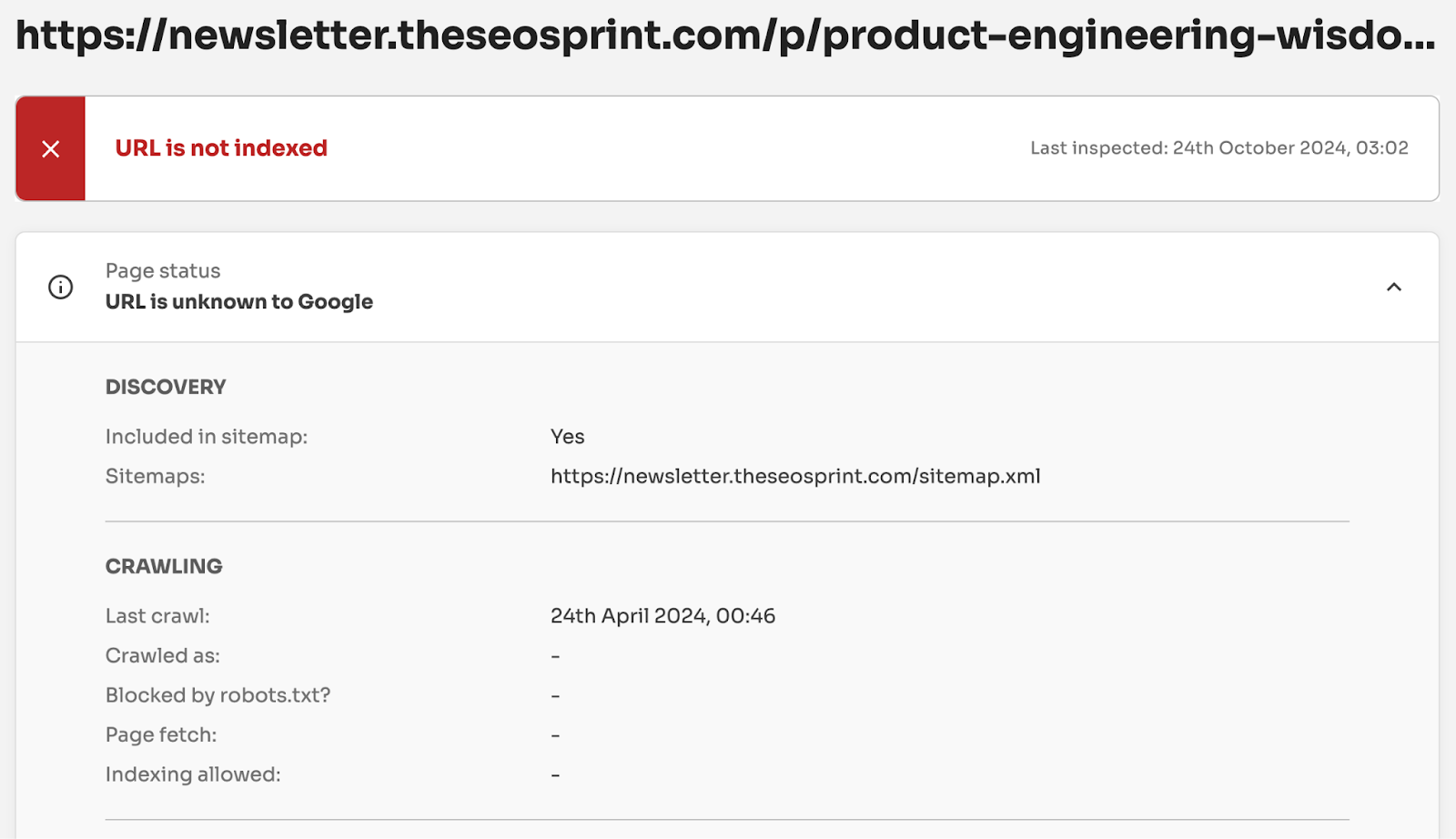
However, if we check the URL in the URL Inspection API, we can see that Google has, in fact, crawled it.
Interestingly, the URL historically also had the indexing state ‘crawled - currently not indexed’ in Google Search Console. This can be tracked in Indexing Insights.
This historical data provides evidence that Google definitely saw this URL.
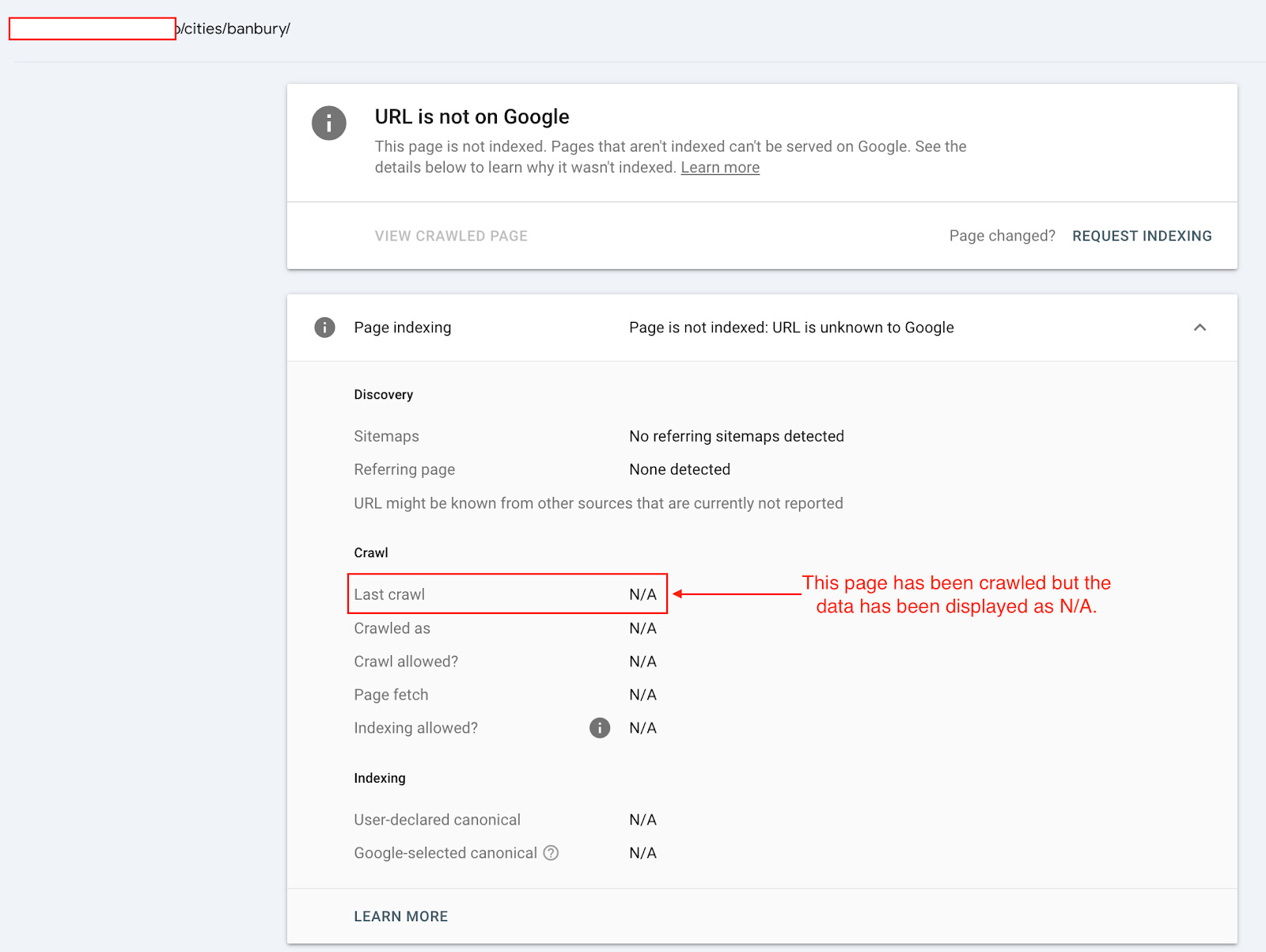
Example #2 - Programmatic SEO website
The second example is from a programmatic SEO website.
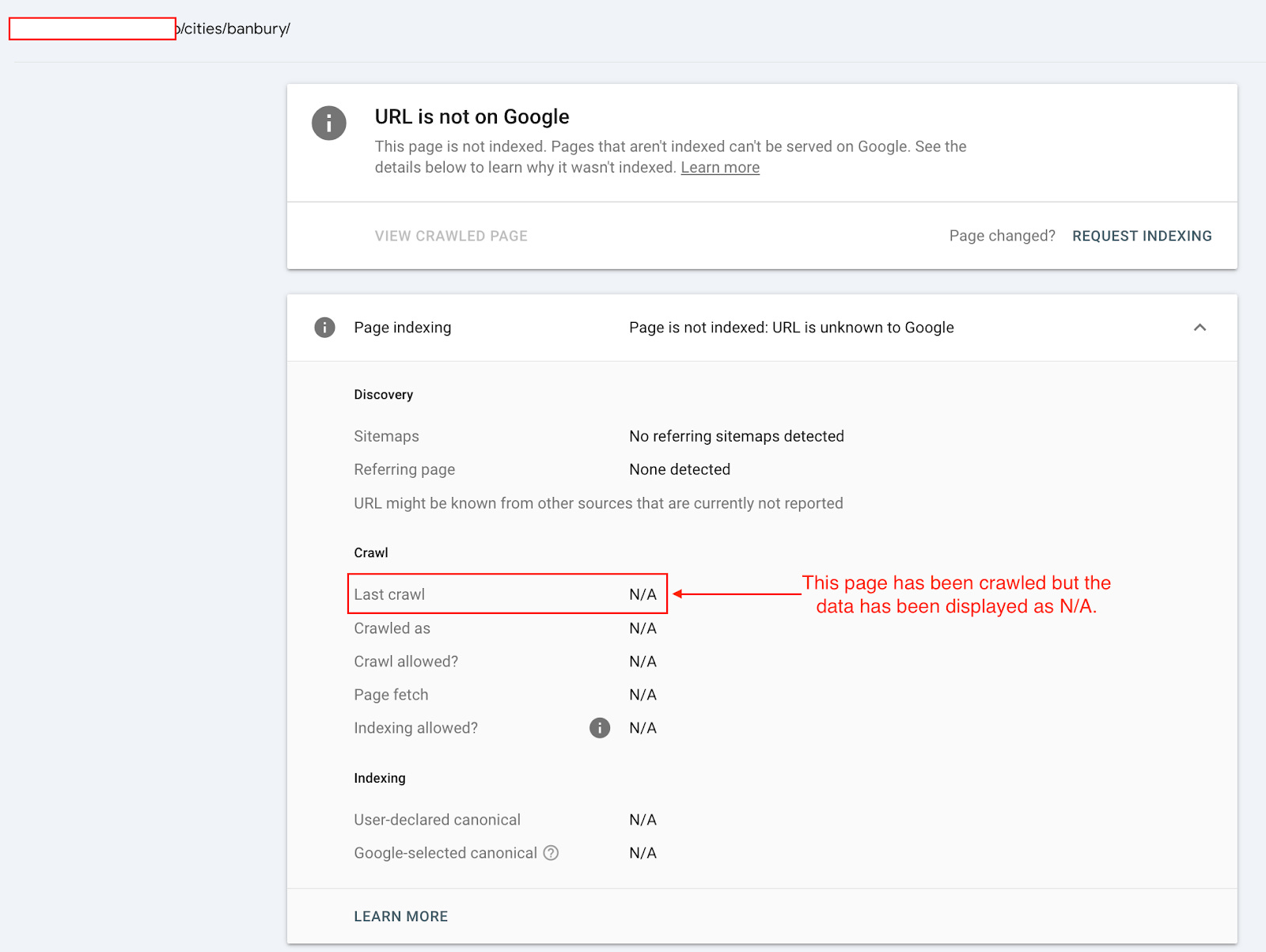
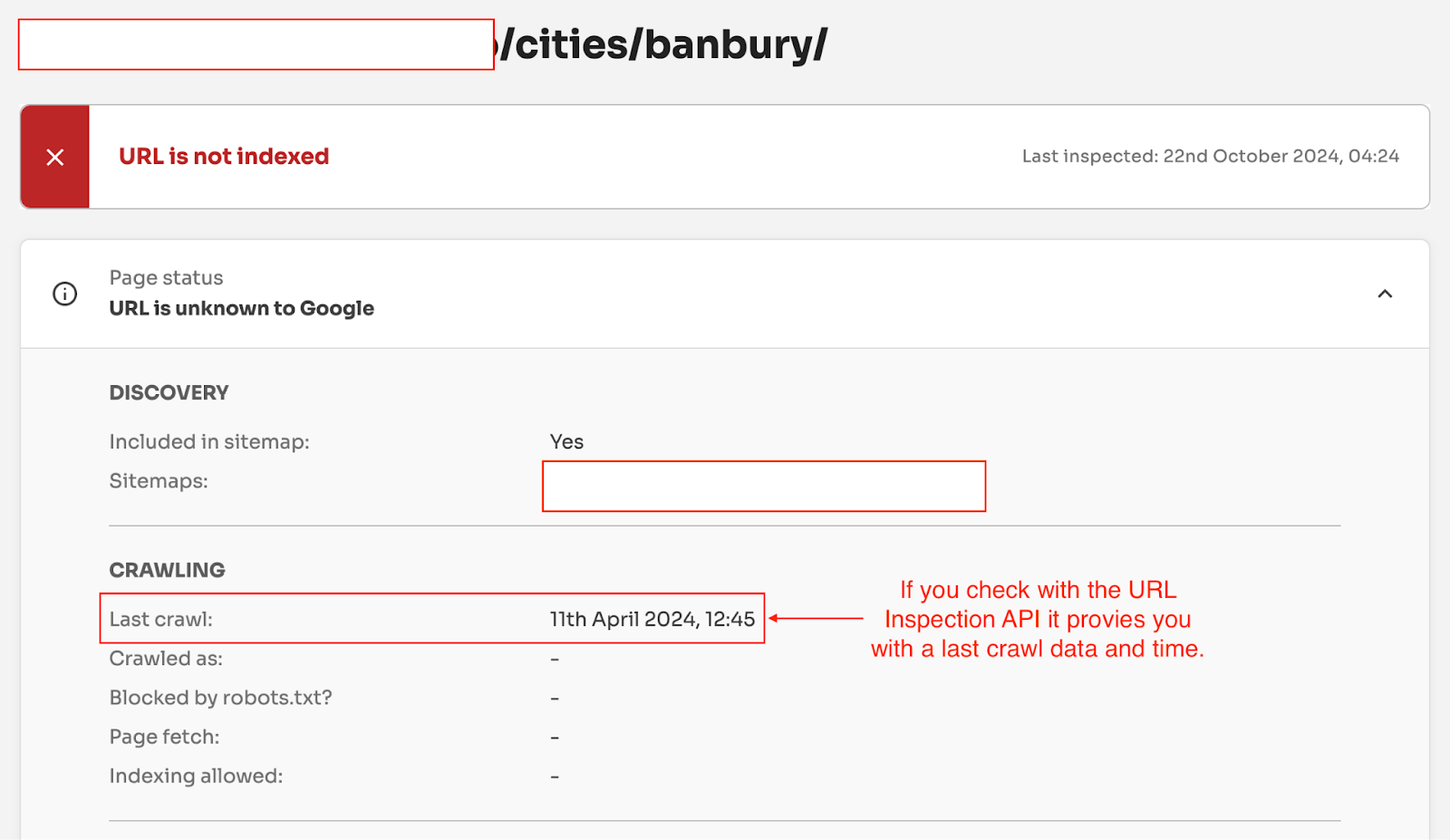
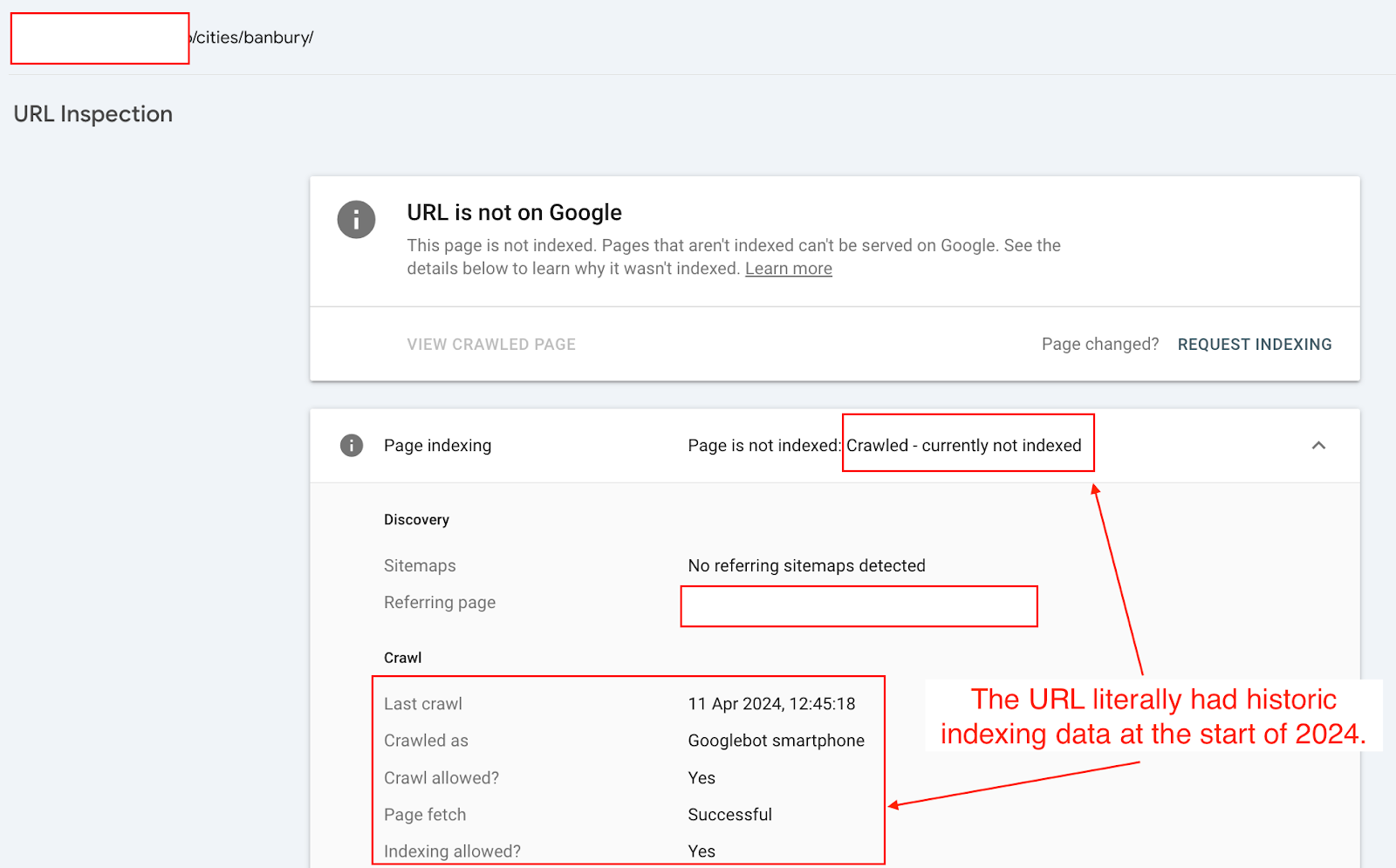
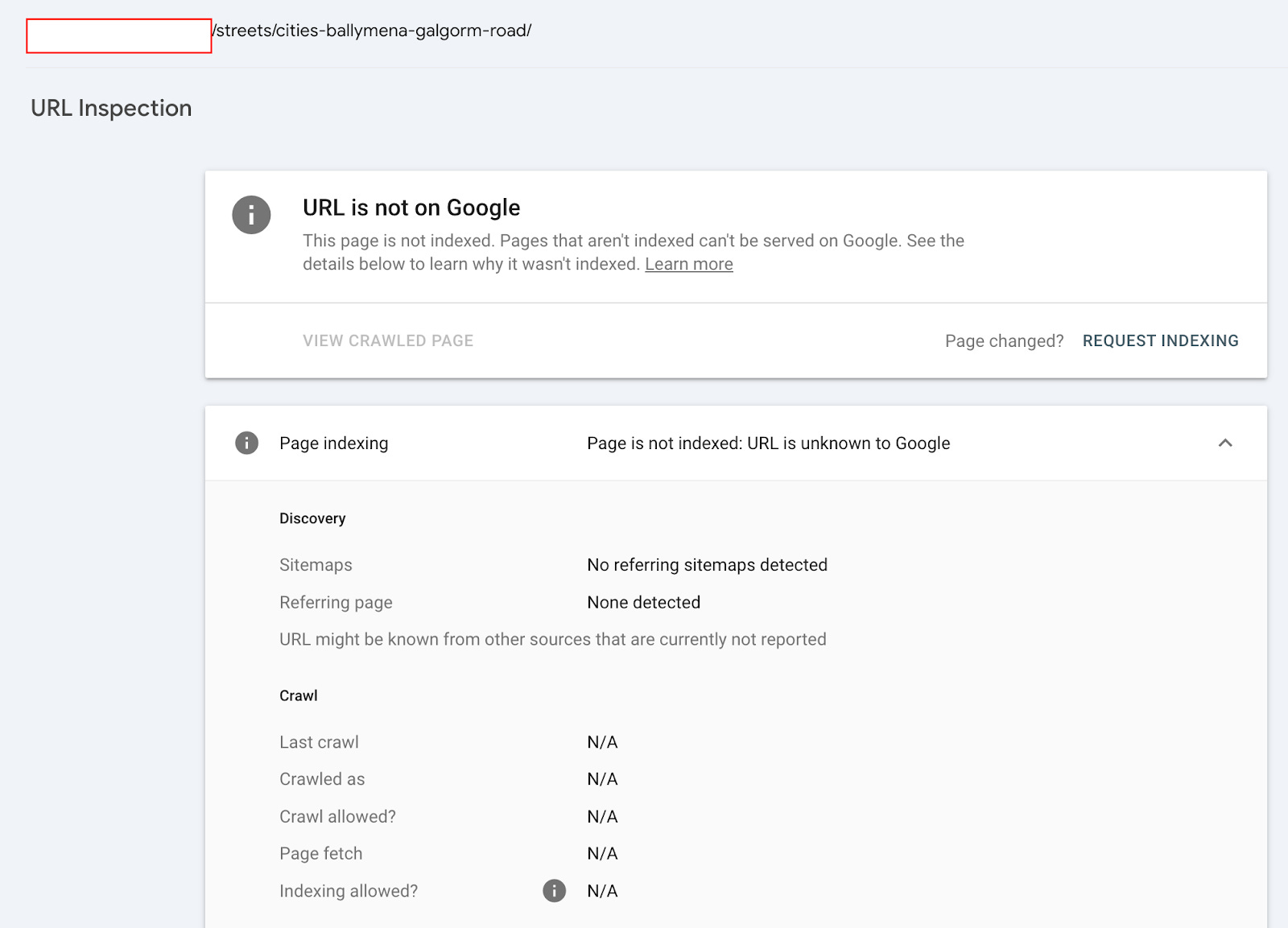
If we test the /cities/banbury/ page using the URL Inspection tool. It gives the coverage state “URL is unknown to Google’.
However, if we check the URL with the URL Inspection API, it gives you a Last Crawl Time.
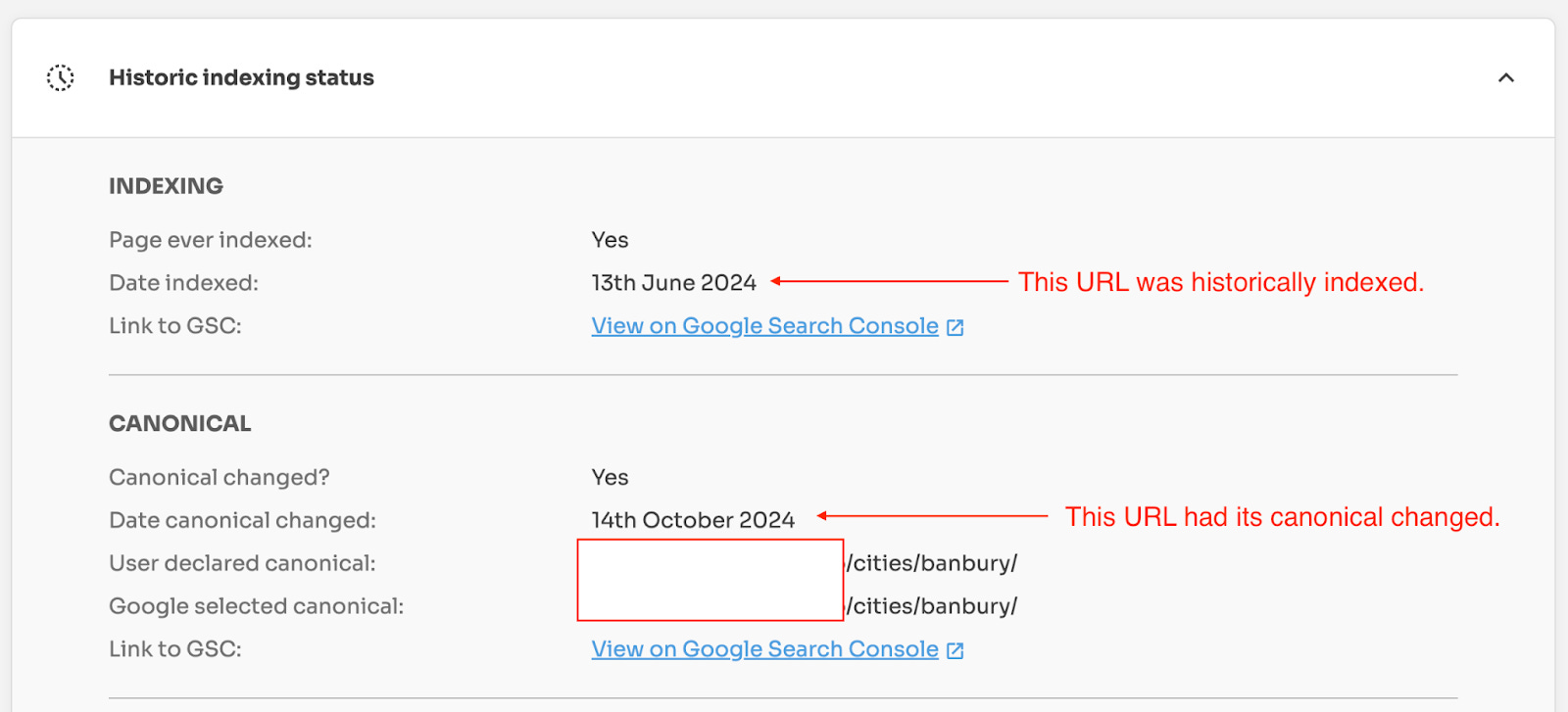
What is even more interesting is that this URL was historically indexed on June 13, 2024, and its canonical URL was dropped (changed) on October 14, 2024.
All of this historical data provides evidence that Google definitely saw this URL.
Indexing Insights provides links to the historic URL Inspection Tool in Search Console. So, you can double-check historic changes in indexing states.
Again, this data shows that Google has definitely seen this URL before.
📈 How often does this happen?
It happens a lot more than you think.
For one alpha tester monitoring 1 million URLs, the state “URL is unknown to Google” accounts for 16% of the total URLs being inspected.
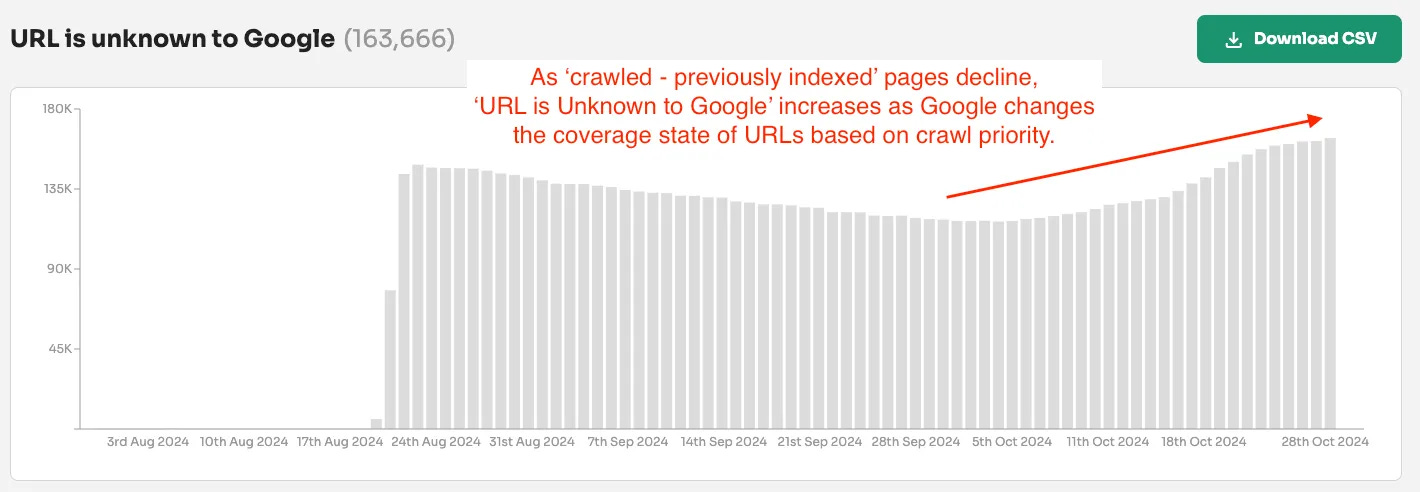
In fact, when writing this newsletter, the ‘URL is unknown to Google’ is increasing…
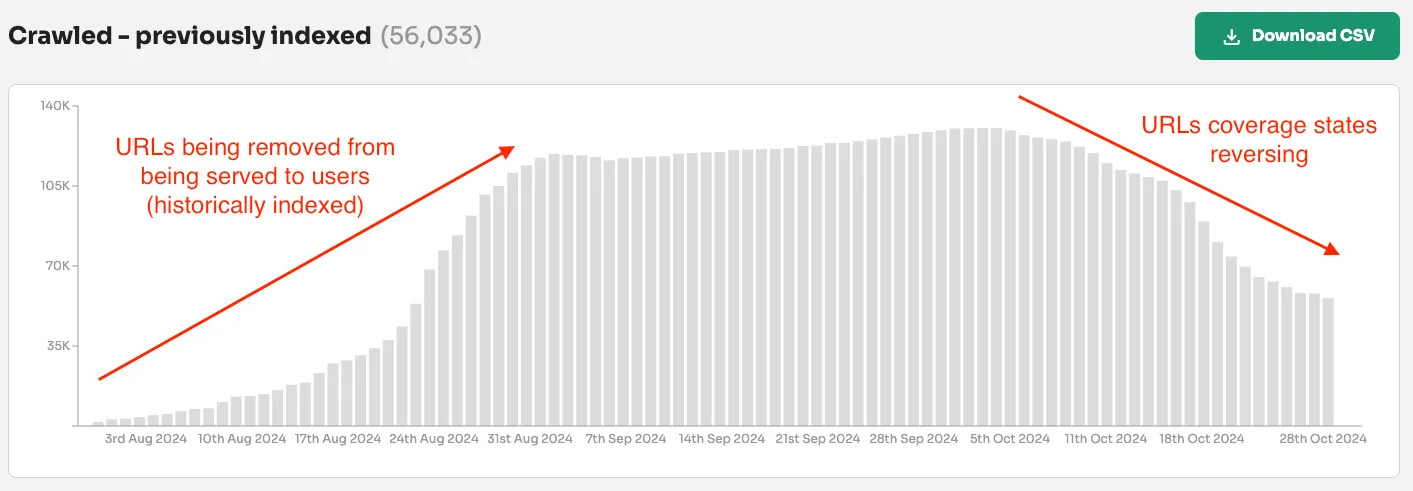
…which is being caused by a decrease in ‘crawled - previously indexed’ submitted pages.
The increase in the number of ‘URL is unknown to Google’ and the decrease in ‘crawled—previously indexed’ indicates that Google has seen these URLs before.
🔎 How can you tell if Google has seen a URL before in GSC?
The URL Inspection API is the only way to check if Google has seen the URL.
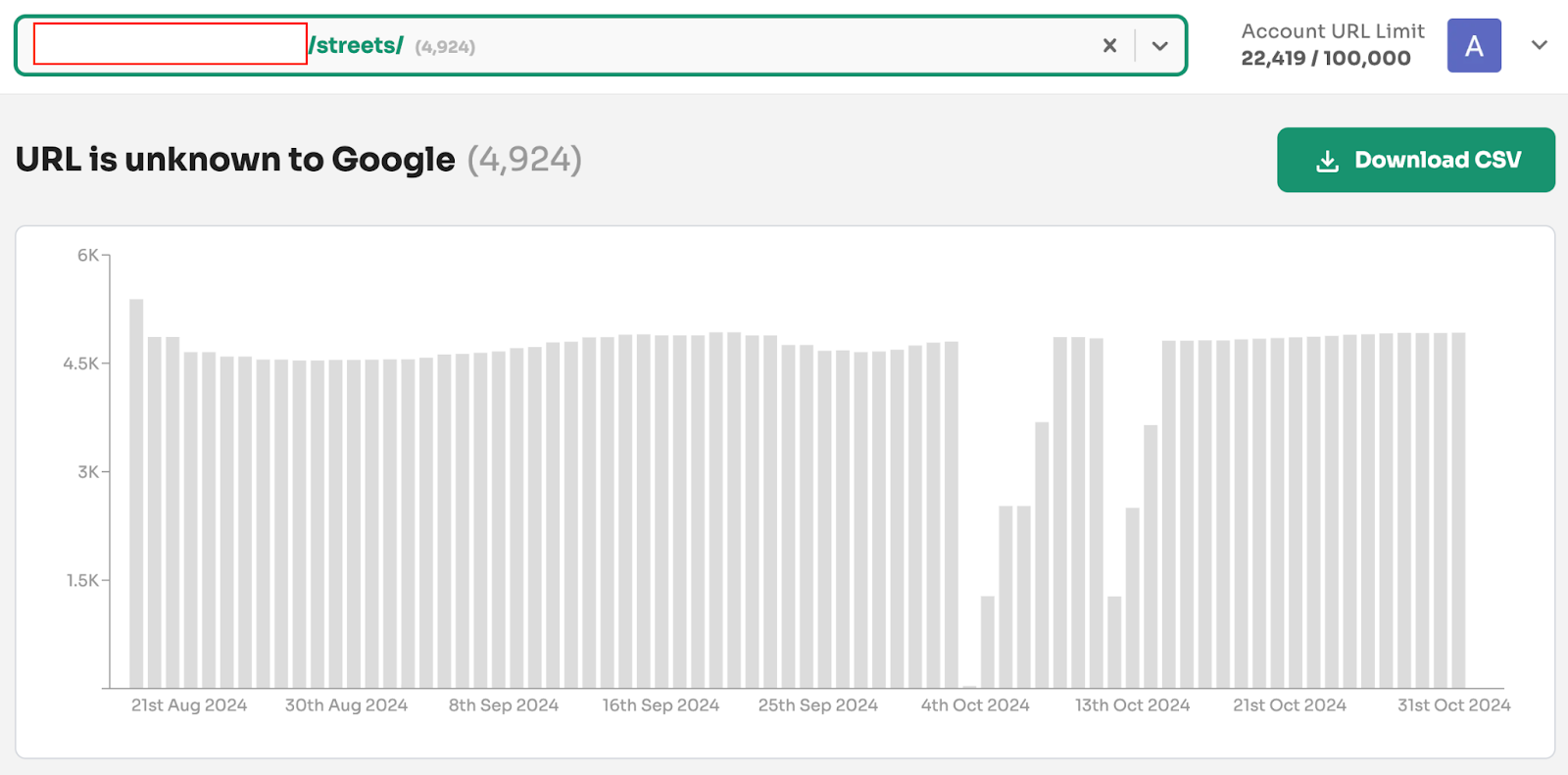
For example, a pSEO website has over 4,900 URLs with the coverage state ‘URL is unknown to Google’...
…but when checking the web property /streets/, you can see the ‘URL is unknown to Google’ coverage state is nowhere to be found.
The only way to check if a page with the state ‘URL is unknown to Google’ has been seen before is to:
Know the URL already exists (e.g. XML Sitemap)
Inspect the URL using the URL Inspection API
Identify if the URL has a last crawl date.
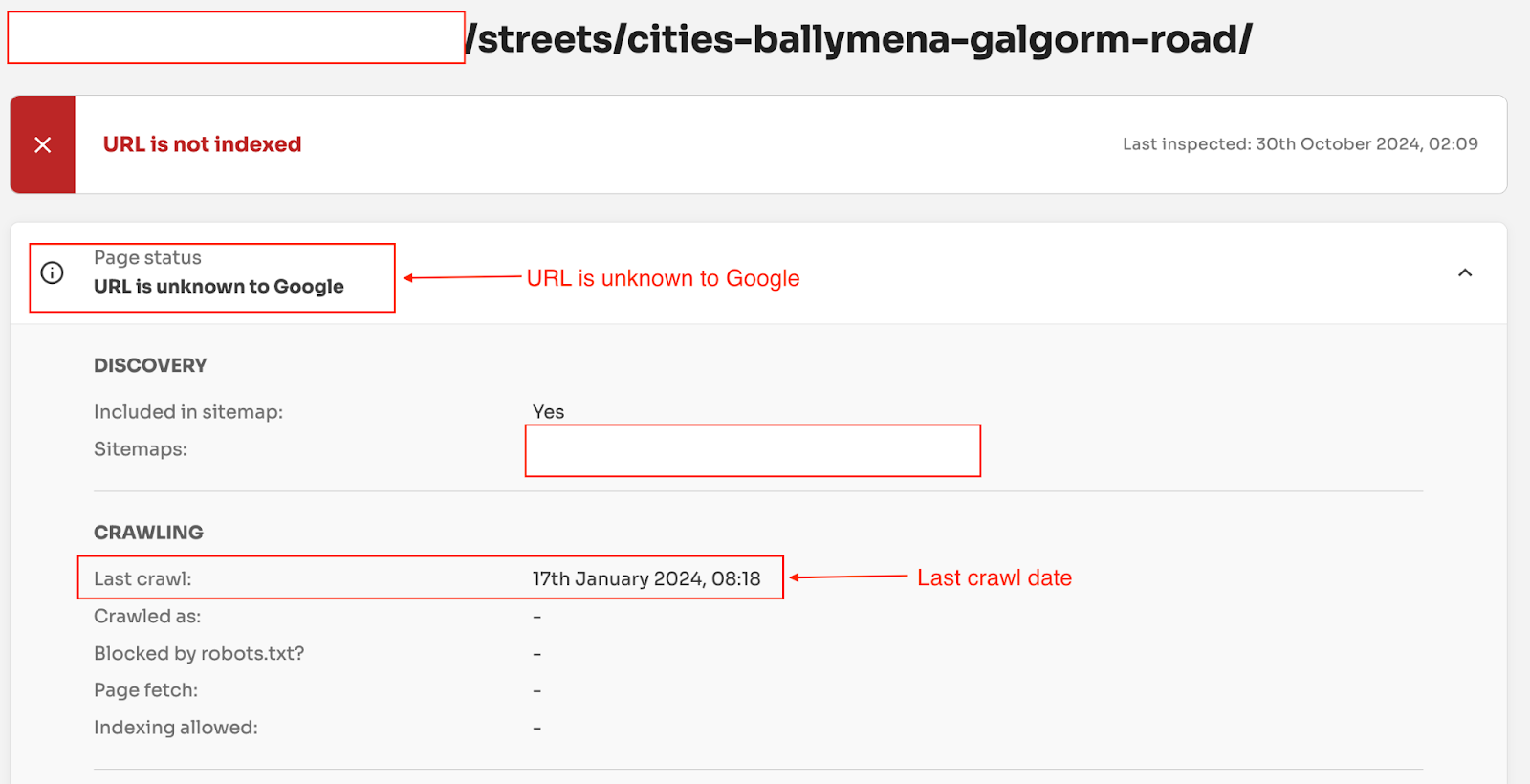
For example, if you try to check for indexing data in Search Console using the URL Inspection tool, it doesn’t show you any data for ‘URL is unknown to Google’.
BUT if you check the same URL using the URL Inspection API, It provides you with the Last Crawl date. And this indicates that Google has seen the URL before.
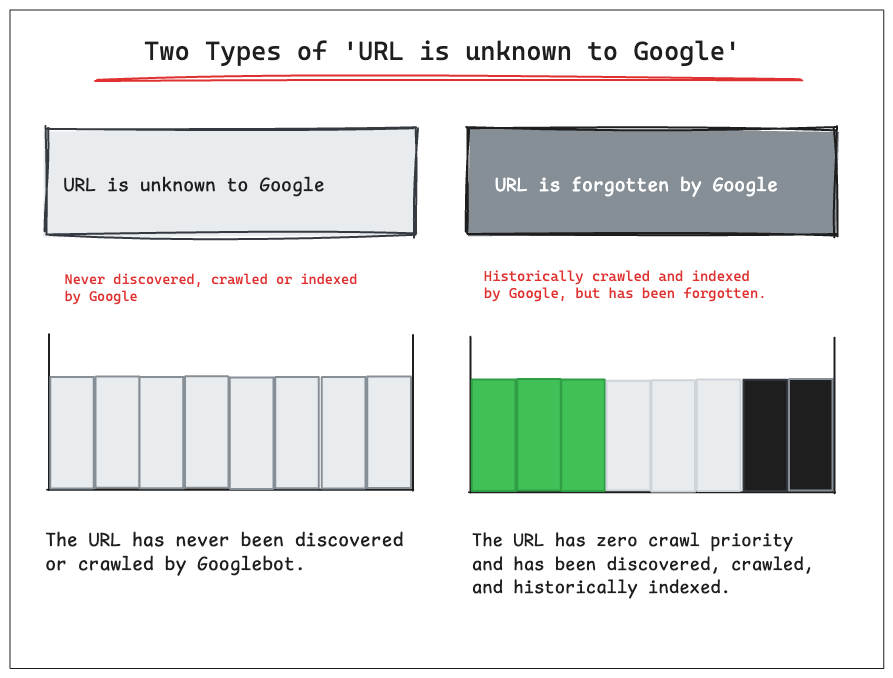
📚 Definition of ‘URL is unknown to Google’ Needs to change
The definition of ‘URL is unknown to Google’ is misleading and needs to change.
URL is unknown to Google - The URL has never been discovered or crawled by Googlebot.
URL is forgotten by Google - The URL was previously crawled and indexed by Google but has been forgotten.
The Indexing Insight data from the URL inspection API shows that Google has seen many submitted URLs before with the coverage state ‘URL is unknown to Google’.
If historically crawled and indexed pages have this state, it is a sign that a URL has experienced reverse indexing over the last 90 - 180 days.
And it is a very low priority to crawl in Google’s crawling system.
📌Summary
The current definition of ‘URL is unknown to Google’ is misleading.
In this newsletter, I’ve provided evidence that just because a page has this state in GSC does not mean Google has never crawled or indexed the URL.
Quite the opposite.
By using Indexing Insight data, we can see that important traffic-driving pages are experiencing reverse indexing. And URLs with the state ‘URL is unknown to Google’ have the least crawl priority in Google’s systems.
The problem is that you can’t detect these problem pages in Search Console.
Hopefully, this newsletter has inspired you to use the URL Inspection API to identify important pages with the ‘URL is unknown to Google’ coverage state.
A page with this coverage state strongly indicates that it is becoming less of a priority for crawling, indexing, and ranking in Google Search.
📊 What is Indexing Insight?
Indexing Insight is a tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
hey Adam, hope you are doing well. Impressive as always.
would be amazing if Indexing Insights could bring the number of pages that had clicks in the past and now are on URL is unknown to Google state...
and also, I think I would suggest the name of the states to be 1) URL was known to Google (when Google reverted its status from indexed to "unknown") and 2) URL was never known to Google (when Google never heard of the URL before)
what I think could be a blocker on their side is that they would need to double check if those specific URLs were ever listed in a specific state, and the little I know about querying a table is that we should always try to limit our searches with a date range... but considering that the report only shows last 90 days, it is a smaller problem...



hey Adam, hope you are doing well. Impressive as always.
would be amazing if Indexing Insights could bring the number of pages that had clicks in the past and now are on URL is unknown to Google state...
and also, I think I would suggest the name of the states to be 1) URL was known to Google (when Google reverted its status from indexed to "unknown") and 2) URL was never known to Google (when Google never heard of the URL before)
what I think could be a blocker on their side is that they would need to double check if those specific URLs were ever listed in a specific state, and the little I know about querying a table is that we should always try to limit our searches with a date range... but considering that the report only shows last 90 days, it is a smaller problem...