
3 Types of Not Indexed Pages in GSC
The 3 common types of Not Indexed error that every SEO professional should know about and how to fix them.

Ever wondered why some of your important pages aren't indexed in Google?
Despite submitting your URLs through XML sitemaps and following best practices, many pages still end up in the dreaded "Not Indexed" category in Google Search Console.
In this newsletter, I'll explain the 3 common types of Not Indexed pages that every SEO professional should know about. And how to identify which category your pages fall into.
So, let's dive in.
🪝 Three Types of Not Indexed Pages
The three types of Not Indexed pages are:
1️⃣ Technical: These Not Indexed errors are about pages that either don't meet Google's basic technical requirements or have directives to stop Google from indexing the page.
2️⃣ Duplication: These Not Indexed errors are about pages that trigger Google’s canonicalization algorithm, and a canonical URL is selected from a group of duplicate pages.
3️⃣ Quality: These Not Indexed errors are about pages that are actively being removed from Google’s search results and, over time, forgotten.

Let’s dive into each one and understand them better!
🆚 Important vs Unimportant Pages
Before we dive in, I want to separate out important and unimportant pages.
When trying to fix indexing issues, you should always separate pages into two types:
🥇 Important pages
😒 Unimportant pages
🥇 Important page
An important page are pages that you want to:
Appear in search results to help drive traffic and/or sales
Help pass link signals to other important pages (e.g. /blog)
For example, if you’re an ecommerce website, you want your product pages to be crawled, indexed and ranked for relevant keywords.
You also want your /blog listing page to be indexed so it passes PageRank (link signals) to your blog posts. So, these important page types can also appear in search results and drive SEO traffic.
😒 Unimportant page
Unimportant pages are pages that you don’t want to:
Appear in search results
Waste Googlebot crawl budget
Help pass link signals to other pages.
This doesn’t mean we just ignore these pages completely. It just means we’re not spending time trying to get these page types indexed in Google.
For example, a lot of ecommerce content management systems (CMS) by default will generate query strings (parameter URLs) which can be crawled and indexed by Google. And we need to properly handle these URLs to help Google not index the pages.
↔️ How do you identify important vs unimportant pages?
The best way to separate important and unimportant pages is with XML sitemaps.
An XML sitemap that contains your important pages submitted to Google Search Console will allow you to filter the page indexing report by submitted (important) vs. unsubmitted (unimportant) pages.

Right, now let’s dive in!
1️⃣ Minimum Technical Requirements
The first type of error is about the minimum technical requirements to get indexed.
What are these types of errors?
These pages either don't meet Google's basic technical requirements or have directives that explicitly tell Google not to index them:
Server error (5xx)
Redirect error
URL blocked by robots.txt
URL marked ‘noindex’
Soft 404
Blocked due to unauthorized request (401)
Not found (404)
Blocked due to access forbidden (403)
URL blocked due to other 4xx issue
Page with redirect
Why are pages grouped into this category?
Google detected that the page does not meet the minimum technical requirements.
For a page to be eligible to be indexed it must meet the following technical requirements:
Googlebot isn't blocked.
The page works, meaning that Google receives an HTTP 200 (success) status code.
The page has indexable content.
If we group the technical errors in Google Search Console, they correspond with one of the minimum requirements:
Googlebot isn't blocked
URL blocked by robots.txt
Blocked due to unauthorized request (401)
Blocked due to access forbidden (403)
URL blocked due to other 4xx issue
Google receives an HTTP 200 (success) status code
Server error (5xx)
Redirect error
Not found (404)
Page with redirect (3xx)
The page has indexable content.
URL marked ‘noindex’
Soft 404
How can you fix these errors?
Generally, these types of Not Indexed pages are within your control to fix.
Now that we’ve grouped these errors under specific categories, it can be easier to identify and address them.
1) Googlebot isn't blocked
If an important page is returning this type of error make sure it can be crawled by Googlebot. An important page can become blocked when:
Robots.txt rule is blocking the page from being crawled
A page has been hidden behind a log-in
A CDN is soft or hard blocking Googlebot
You can test if an important page is blocked using Robots.txt parser tool and read more about how to debug CDNs and crawling.
2) Google receives an HTTP 200 (success) status code
If an important page is NOT returning a HTTP 200 (success) status code then Googlebot will not index the page.
There are 3 reasons an important page is returning non-200 status code:
The non-200 status is not intentional (and needs to return a 200 status code)
The non-200 status is intentional (and the XML sitemap has not been updated)
The page is returning a 200 status code but Googlebot has not recrawled the page.
If an important page is unintentionally returning a non-200 status code it could because the page was 3xx redirected, returning a 4xx or a 5xx error. You can read more about how different HTTP status code impact Googlebot.
A JavaScript website can also return incorrect status codes for important pages. You can read more about JavaScript SEO best practices and HTTP status codes in Google’s official documentation.
Finally, don’t panic if Google is returning a non-200 HTTP status code error for one of your important pages. Especially if you know the page (or pages) were changed recently.
Sometimes, Googlebot hasn’t crawled the page, or the reports take time to catch up with the changes made to your website.
Check with the Live URL test in the URL inspection tool in Google Search Console.
3) The page has indexable content
Finally, if your important pages do not have indexable content it is usually because:
Googlebot discovered a noindex tag on the page.
Googlebot analysed the content and believes it is a soft 404 error.
If an important page has a noindex tag (meta robots or X-robots) then Google will not render or index the page. You can learn more about the noindex tag on Google’s official documentation.
If an important page has a Soft 404 error then this means that Google believes the content should return a 404 error. This usually happens because Google is detecting similar minimal content across multiple pages that make it think the pages should be returning a 404 error.
You can learn more about fixing soft 404 errors in Google’s official documentation.
2️⃣ Duplicate Content
The second type of not indexed pages relate to duplicate content issues.
What are these types of errors?
These types of errors are to do with Google canonicalization process in the indexing pipeline (I’ve provided descriptions as these are a bit more complicated):
Alternate page with proper canonical tag - The page has indicated that another page is the canonical URL that will appear in search results.
Duplicate without user-selected canonical - Google has detected that this page is a duplicate of another page, that it does not have a user-selected canonical and that they have chosen another page as the canonical URL.
Duplicate, Google chose different canonical than user - Although you have specific another page as the canonical URL, Google has chosen a different page as the canonical URL to appear in search results.
Why are pages grouped into this category?
Pages are grouped into this category because of Google’s canonicalization algorithm.
When Google identifies duplicate pages across your website it:
Groups the pages into a cluster.
Analyses the canonical signals around the pages in the cluster.
Selects a canonical URL from the cluster to appear in the search results.
This process is called canonicalization. However, the process isn't static.
Google continuously evaluates the canonical signals to determine which URL should be the canonical URL for the cluster. It looks at:
3xx Redirects
Sitemap inclusion
Canonical tag signals
Internal linking patterns
URL structure preferences
If a page was previously the canonical URL but new signals make Google select another URL in the cluster, then your original page gets removed from search results.

How can you fix these errors?
These types of Not Indexed pages are within your control to fix.
There are 3 reasons why your important pages are appearing in these categories:
Important pages don’t have a canonical tag.
Important page’s have been duplicated due to website architecture.
Important page’s canonical signals lack consistency across the website.
Duplicate without user-selected canonical
If an important page (or pages) does not have a canonical tag, then this can cause Google to choose a canonical URL based on weaker canonical signals.
Always make sure you specific the canonical URL by using canonical tags. For further information you can read how to specify a canonical link in Google’s documentation.
Duplicate, Google chose different canonical than user
If the signals around an important page aren’t consistent then this can cause Google to pick another URL as the canonical URL in a cluster.
Even if you use a canonical tag.
You need to ensure canonical signals are consistent across your website for the URLs you want to appear in search results. Otherwise, Google can, and will, choose the canonical URL for you. And it might not be the one you prefer.
Google provides documentation on how to fix canonical issues in its official documentation.
3️⃣ Quality Issues
The final type of not indexed page relates to quality issues, and these are the most challenging to address.
What are these types of errors?
These types of indexing errors are split into 3 groups based on the signals collects around pages over time:
Crawled - currently not indexed: The page has either been discovered, crawled but not indexed OR the historically indexed page has been actively removed from Google’s search results.
Discovered—currently not indexed: A new page has been discovered but not yet crawled, OR Google is actively forgetting the historically indexed page.
URL is unknown to Google: A page has never been seen by Google OR Google has actively forgotten the historically crawled and indexed pages.
Why are pages grouped into this category?
Google is actively removing these pages from its search results and index.
In another article, we discussed how Google might actively manage its index. The article discusses a patent that describes two systems: importance thresholds and soft limits.
The soft limit sets a target for the number of pages to be indexed. And the importance threshold directly influences which URLs get crawled and indexed.
Here's how it works according to the patent when the soft limit is reached:
Pages with an importance rank equal to or greater than the threshold are indexed.
As the threshold dynamically adjusts, URLs' crawl and indexing priority changes.
URLs with an importance rank far below the threshold have zero crawl priority.
This system explains why some pages move from the "Crawled—currently not indexed" to the "URL is Unknown to Google" indexing states in Google Search Console.
It's all about their importance rank relative to the current threshold.

You need to group the two types of important pages within this category to avoid actioning unimportant pages:
✅ Indexable: Live important pages that are indexable but are not indexed.
❌ Not Indexable: Important pages that are not indexable (301, 404, noindex, etc.)
Why do we need to distinguish between these 2-page types in Google Search Console?
Our first-party data has shown that a small % of pages that are not indexable over time can be grouped into these categories.
For example, an ‘Excluded by nonindex tag’ can become ‘Crawled - currently not indexed’ after roughly 6 months. This isn’t a bug but by design.
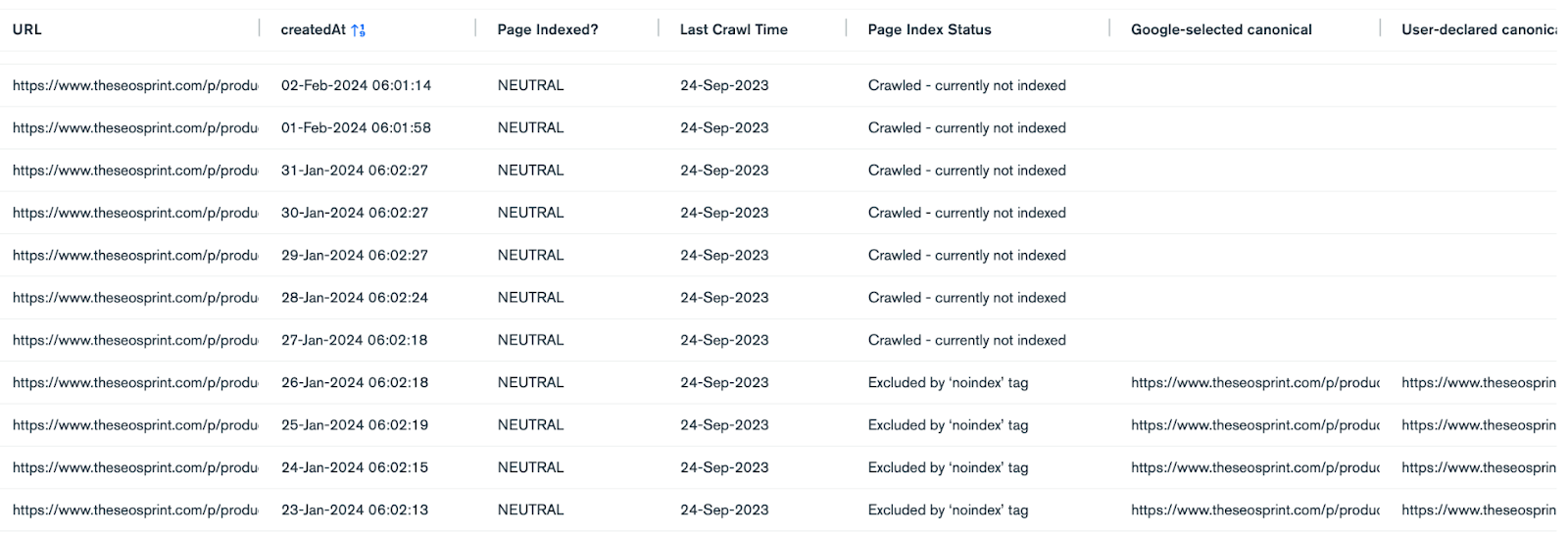
When trying to figure out why pages are grouped into this category, it’s important to distinguish between what pages are Indexable and Not Indexable.
How can you fix indexable page errors?
Important indexable pages that are not indexed will be harder to fix.
Why?
If a page is live, indexable, and meant to be ranked in Google search and is underneath this category, then it means the website has bigger quality problems.
According to Google, they actively forget low-quality pages due to signals picked up over time.
There are 2 types of signals that can influence why Google might forget your important indexable pages:
📄 Page-level signals
🌐 Domain-level signals
📄 Page-level signals
The page-level signals can be grouped into three problems:
The indexable pages do not have unique indexable content.
The indexable pages are not linked to from other important pages.
The indexable pages weren’t ranking for queries or driving relevant clicks.
Why these three page-level signals in particular?
Google itself describes the 3 big pillars of ranking are:
📄 Content: The text, metadata and assets used on the page.
🔗 Links: The quality of links and words used in anchor text pointing to a page.
🖱️ Clicks: The user interactions (clicks, swipes, queries) for a page in search results.
In the DOJ trial, Google provided a clear slide highlighting that content (vector embeddings), user interactions (click models) and anchors (PageRank/anchor text) play a key role across all their systems.
A BIG signal used in ranking AND indexing is user interaction data.
The DOJ documents describe how Google uses “user-side data” to determine which pages should be maintained in its index. Also, another DOJ trial document mentions that the user-side data, specifically the query data, determines a document's place in the index.
Query data for specific pages can indicate if a page is kept as “Indexed” or “Not Indexed”.
What does this mean?
This means that for important pages, you must include unique indexable content that matches user intent and build links to the page with verified anchor text. These pillars are essential to help you rank for a set of queries searched for by your customers.
However, user interaction with your page will likely decide whether it remains indexed over time.
When reviewing your important indexable pages that Google is actively removing, look at:
Indexing Eligibility: Check if Googlebot can crawl the page URL and render the content using the Live URL test in the URL inspection tool in Google Search Console.
Content quality: Check if the page or pages you want to rank match the quality and user intent of the target keywords (great article from Keyword Insights on this topic).
Internal links to the page: Check if the pages are linked to from other important pages on the website and you’re using varied anchor text (great article from Kevin Indig on this topic).
User experience: Check if your important pages actually provide a good user experience, load quickly, and answer the user’s question (great article from Seer Interactive on this topic).
🌐 Domain-level signals
However, page-level signals aren’t the only factor at play.
New research by SEO professionals has found that domain-level signals like brand impact a website’s ability to rank, which, as mentioned above, eventually impacts indexing.
The domain-level signals can be grouped into three areas:
The pages are part of a sitewide website quality issue.
The pages are on a website that is not driving any brand clicks.
The pages/website are not linked to other relevant, high-quality websites.
Mark Williams Cook and his team identified an API endpoint exploit that allowed them to manipulate Google’s network requests. This exploit allowed his team to extract metrics for classifying websites and queries in Google Search.
One of the most interesting metrics extracted was Site Quality score.
The Site Quality score is a metric that Google give each subdomain ranking in Google search and is scored from 0 - 1.

One of the most interesting points from Mark’s talk is that when analysing a specific rich result, his team noticed that Google only shows subdomains above a Site Quality score threshold.
For example, his team noticed that sites with a site quality score lower than 0.4 were NOT eligible to appear in rich results. No matter how much you “optimise” the content, you can’t appear in rich results without a site quality greater than 0.4.

What makes up the Site Quality score?
Mark pointed out a Google patent called Site Quality Score (US9031929B1) that outlines 3 metrics that can be used to calculate the Site Quality score.
The 3 metrics that influence Site Quality score:
Brand Volume - How often people search for your site alongside other terms.
Brand Clicks - How often people click on your site when it’s not the top result.
Brand Anchors - How often your brand or site name appears in anchor text across the web.
What if you’re a brand new website?
Mark pointed to a helpful Google patent called Predicting Site Quality (US9767157B2**),** which outlines 2 methods for predicting site quality scores for new website’s.
The 2 methods for predicting Site Quality score for new websites:
Phrase Models: Predicts site quality by analysing the phrases present within a website and comparing them to a model built from previously scored sites.
User Query Data: Using historic click models, predict the site quality score based on how users interact with the particular website.
Is there any data or research that backs up the Site Quality Score?
Interestingly, Tom Capper at Moz studied Google core updates and found that the Help Content Update (HCU) impacted websites with a low brand authority vs domain authority ratio.
This means that core updates impacted sites with a low brand authority more heavily.
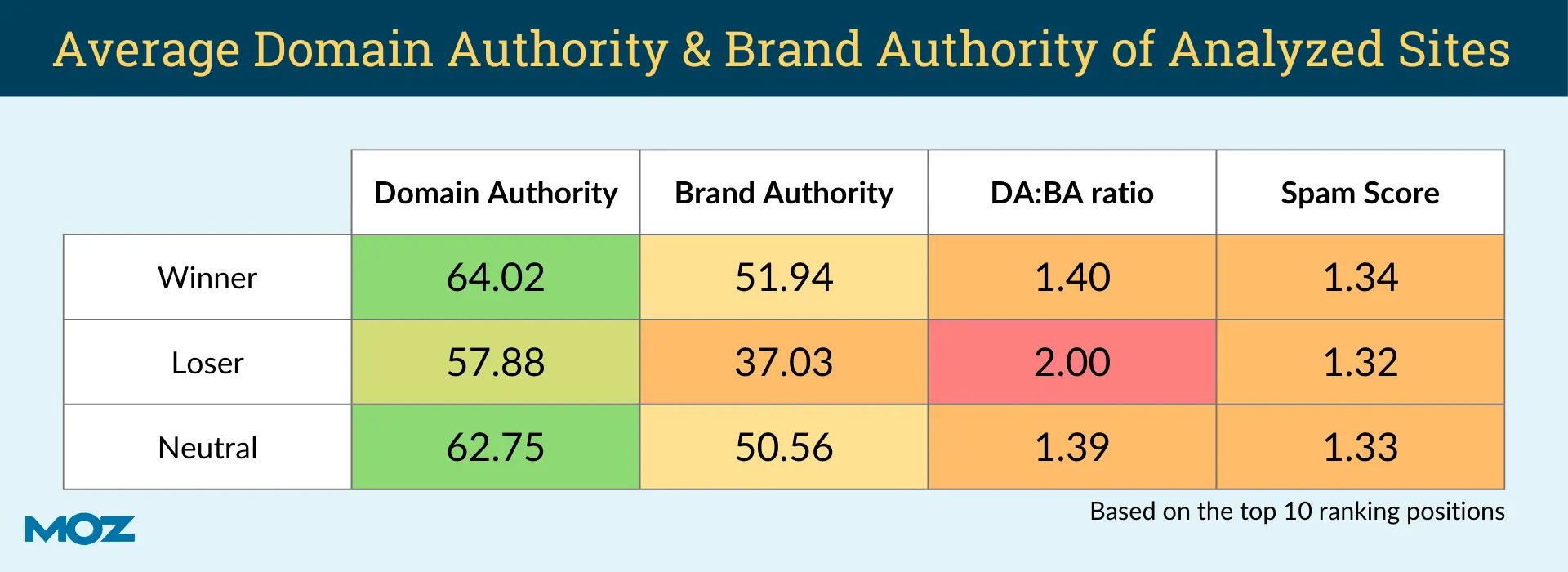
Google doesn’t use the brand authority metric from Moz in its ranking algorithms. However, Tom’s study shows a connection between your domain's brand “authority” and a website’s ability to rank in Google Search.
Why does any of this site quality or brand authority matter to indexing?
Let me lay it all out for us to think it through:
Google uses indexable content, anchor text and links to rank pages for queries.
Over time, Google uses “user-side data” (click models/query data) to determine if a page remains in its index at a page level.
Google tracks the site quality score of your subdomain (website), and only sites above a certain threshold (=> 0.4) can appear in features like rich results.
Based on a Google patent, the site quality score is calculated using brand volume, clicks and interactions (as well as predicting scores for new websites).
Based on Moz’s research, The Google Help Content Update (HCU) impacts websites with low brand authority but high backlink authority.
If a website or pages are affected by Google updates (like the HCU), they will not rank for user queries and will have less “user-side data” over time.
The less “user-side data” over time, the greater the chance that Google’s search index will decide to remove the page from search results actively.
Domain-level signals like brand and backlinks help important indexable pages rank in search.
By ranking in search results, your important pages will get “user-side data” (clicks/queries), increasing the chance of your pages remaining in Google’s index.
Domain-level signals drive rankings, impacting whether important pages remain in the index.
If your page-level changes are not improving the indexing status of your important pages, you might need to work on building the website and brand's authority.
It’s why so many enterprise websites suffer from index bloat.
Google is happy to crawl and index lower-quality pages on websites with higher site quality scores (but that’s an issue for another newsletter).
It sucks but the reality is that Google prefers to rank brands over small websites.
📌 Summary
There are 3 main types of not indexed pages: technical barriers, duplicate content issues, and quality problems.
Technical barriers and duplicate content issues are generally within your control to fix through standard optimization practices.
Quality issues, however, require deeper analysis and often signal more significant problems with how your content meets user and search engine expectations.
Regularly monitoring your indexation status is crucial to identifying which category your not indexed pages fall into and taking appropriate action.