
How Google Manages its Search Index
How Google decides to actively remove your pages based on the insights from a patent titled "Managing URLs" (US7509315B1).

Indexing Insight helps you monitor Google indexing for large-scale websites. Check out a demo of the tool below 👇.
Google actively manages its index by removing low-quality pages.
In this newsletter, I'll explain insights from Google's patent "Managing URLs" (US7509315B1) on how Google might manage its search index.
I'll break down the concepts of importance thresholds, crawl priority, and the deletion process. And how you can use this information to spot quality issues on your website.
So, let's dive in.
⚠️ Before we dive in remember: Just because it’s in a Google patent doesn’t mean that Google engineers are using the exact systems mentioned in US7509315B1.
However, it does help build foundational knowledge on how Informational Retrival (IR) professionals think about managing a massive general search engine’s search index. ⚠️
📚 What is the Search Index?
Google’s search index is a series of massive databases that store information.
To quote Google’s official documentation:
“The Google Search index covers hundreds of billions of webpages and is well over 100,000,000 gigabytes in size. It’s like the index in the back of a book - with an entry for every word seen on every webpage we index.” - How Google Search organizes information
When you do a search in Google, the list of websites returned in Google’s search results comes from its search index.
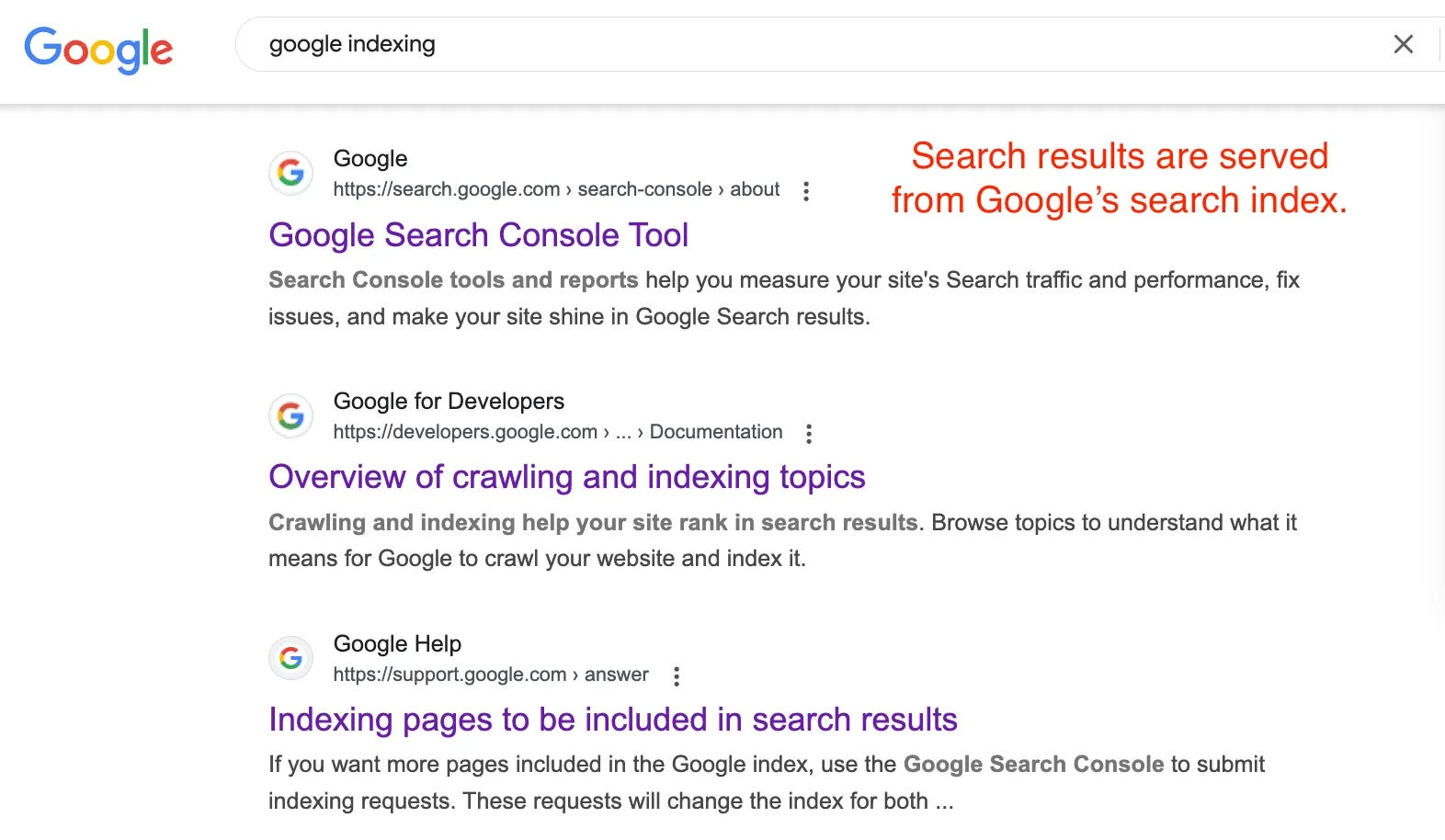
The process of building its search results is done in a 3-step process (source):
🕷️ Crawling: Google uses automated web crawlers to discover and download content.
💽 Indexing: Google analyses the content and stores it in a massive database.
🛎️ Serving: Google serves the stored content found in its search results.
If a website’s page is not indexed, it cannot be served in Google’s search results.
Any SEO professional or company can view the indexing state of their website’s pages in the Page Indexing report in Google Search Console.
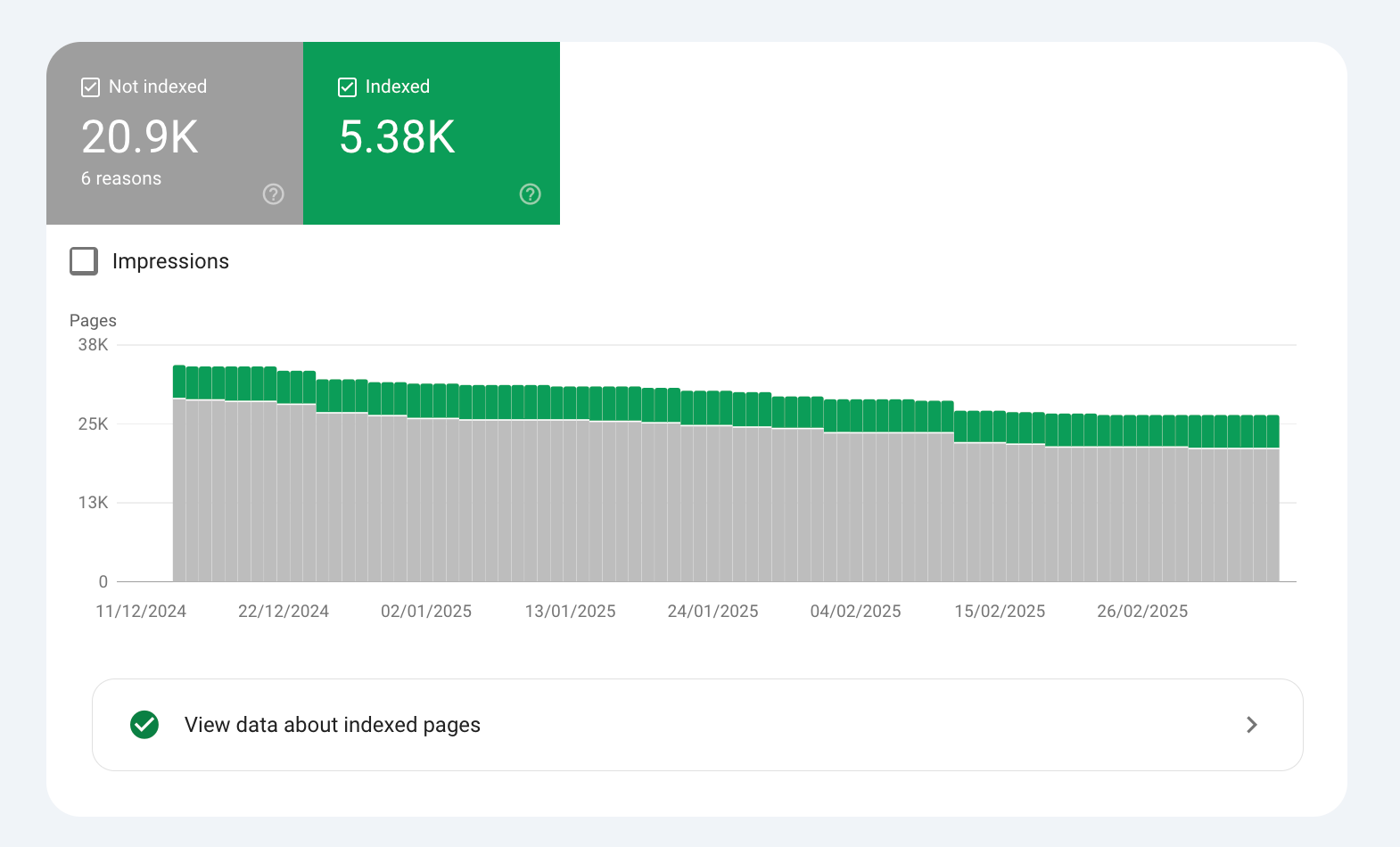
🤖 Google Search Index Quality
Google actively removes pages from its search index.
This isn’t a new concept or idea. Lots of SEO professionals and Googler’s have flagged this over the last decade (but you have to really go looking). A few examples below.
Gary Illyes has mentioned in interviews that Google actively removes pages from its index:
“And in general, also the the general quality of the site, that can matter a lot of how many of these crawled but not indexed, you see in Search Console. If the number of these URLs is very high that could hint at a general quality issues. And I've seen that a lot uh since February, where suddenly we just decided that we are de-indexing a vast amount of URLs on a site just because the perception, or our perception of the site has changed.” - Google Search Confirms Deindexing Vast Amounts Of URLs In February 2024
Martin Splitt put out a video explaining Google actively removes pages from its index:
“The other far more common reason for pages staying in "Discovered-- currently not indexed" is quality, though. When Google Search notices a pattern of low-quality or thin content on pages, they might be removed from the index and might stay in Discovered.” - Help! Google Search isn’t indexing my pages
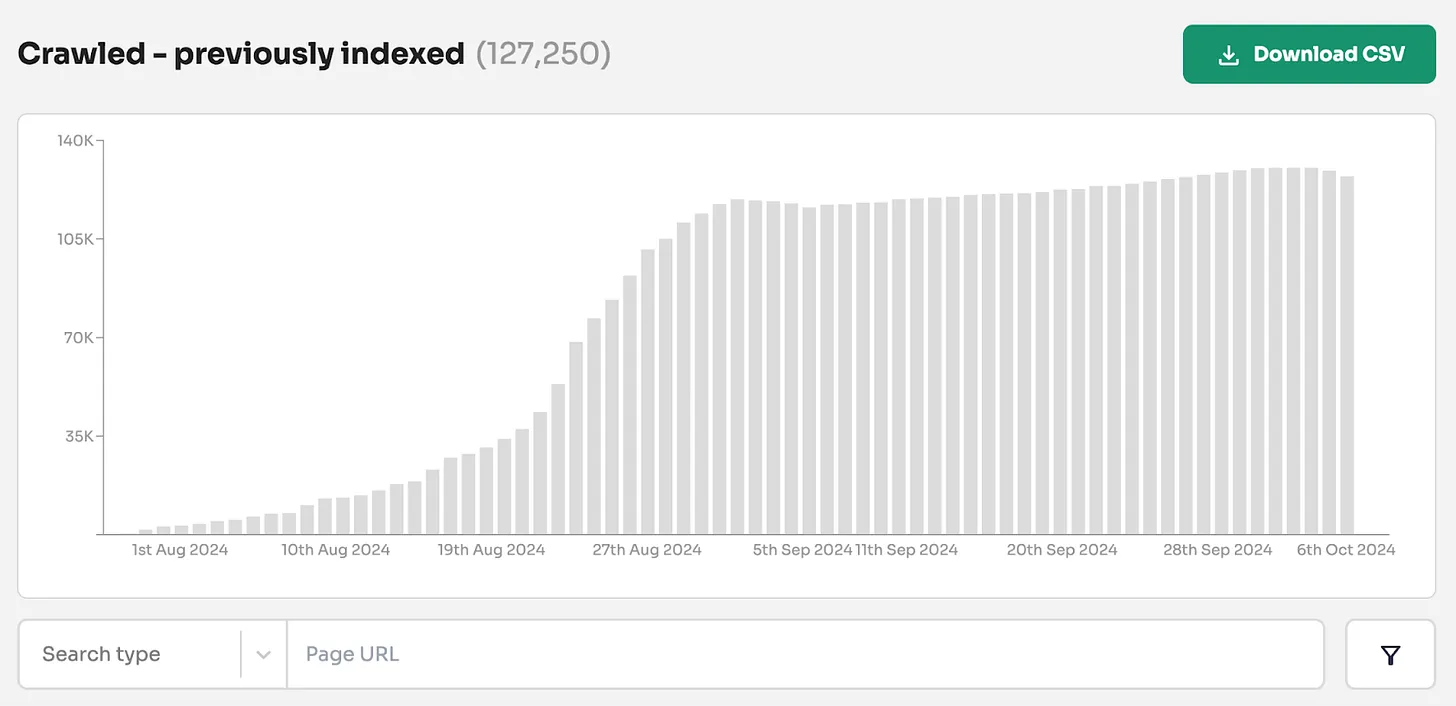
Indexing Insight first-party data shows that pages are actively removed from the index using our unique ‘Crawled - previously indexed report’:
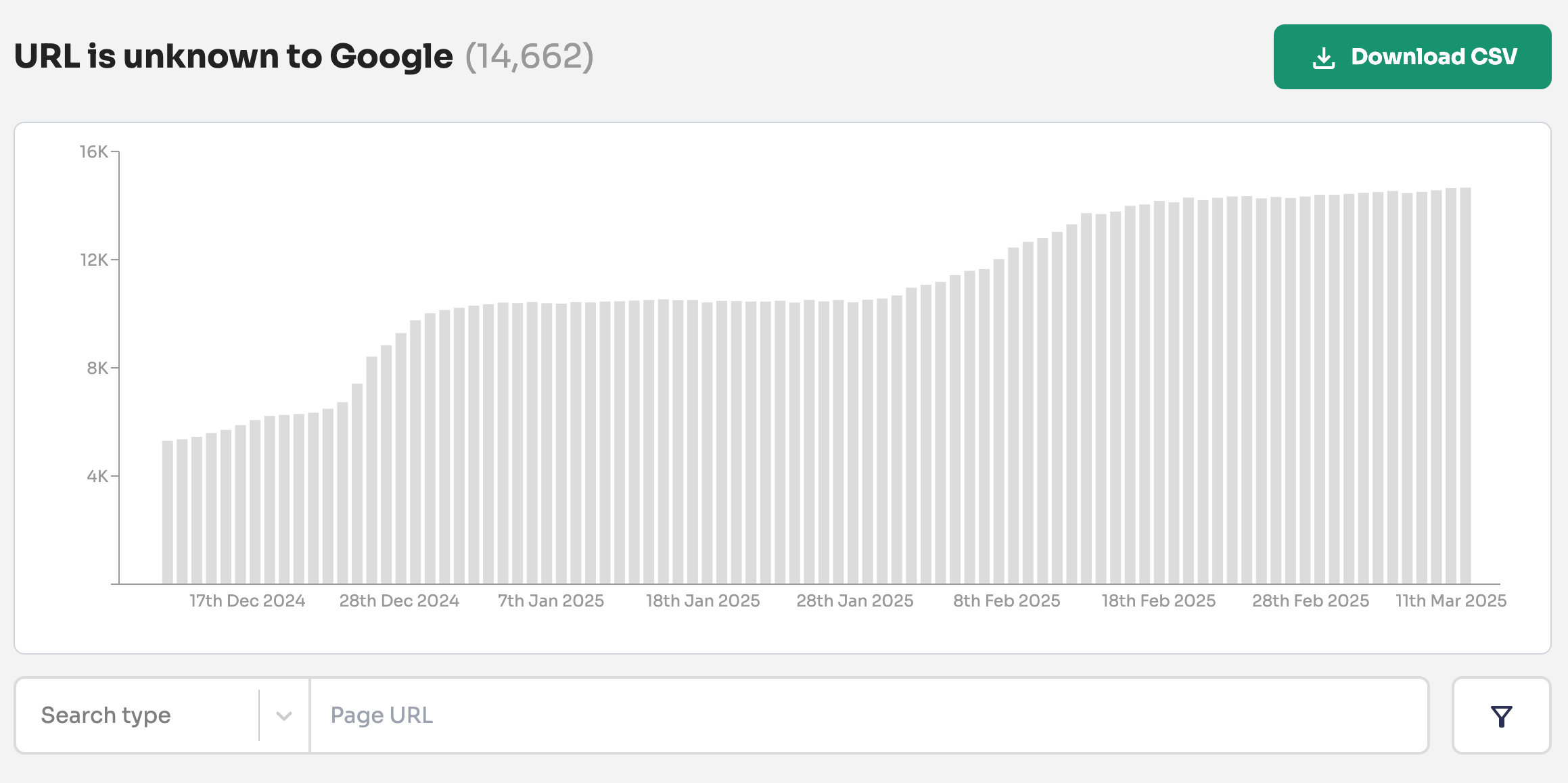
And our first-party data shows that Google actively forgets URLs that were previously crawled and indexed:
But how does Google decide which pages to remove from it’s index?
A Google patent called "Managing URLs" (US7509315B1) might hold the answer to how a search giant like Google manages its mammoth Search Index.
🔍 Search Index Limit
Any database (like a Search Index) has limits.
According to the Google patent "Managing URLs" (US7509315B1), any search index comes with limits for the number of pages that can be efficiently indexed.
There are two different limits to managing a search engine’s index effectively:
Soft Limit: This limit sets a target for the number of pages to be indexed.
Hard Limit: This limit acts as a ceiling to prevent the index from growing excessively large.
These two limits work together to ensure Google's index remains manageable while prioritizing high-ranking documents.
However, reaching this limit doesn't mean a search engine stops crawling entirely.
Instead, it continues to crawl new pages but only indexes those deemed "important" enough based on query-independent metrics (e.g. PageRank, according to the patent).
This leads us to an interesting concept: the importance threshold.
⚖️ The importance threshold
The importance threshold is a benchmark score mentioned in the Google patent.
It describes that a new page should be indexed after the initial limit has been reached. Only pages with an importance score equal to or higher than this threshold are added to the index.
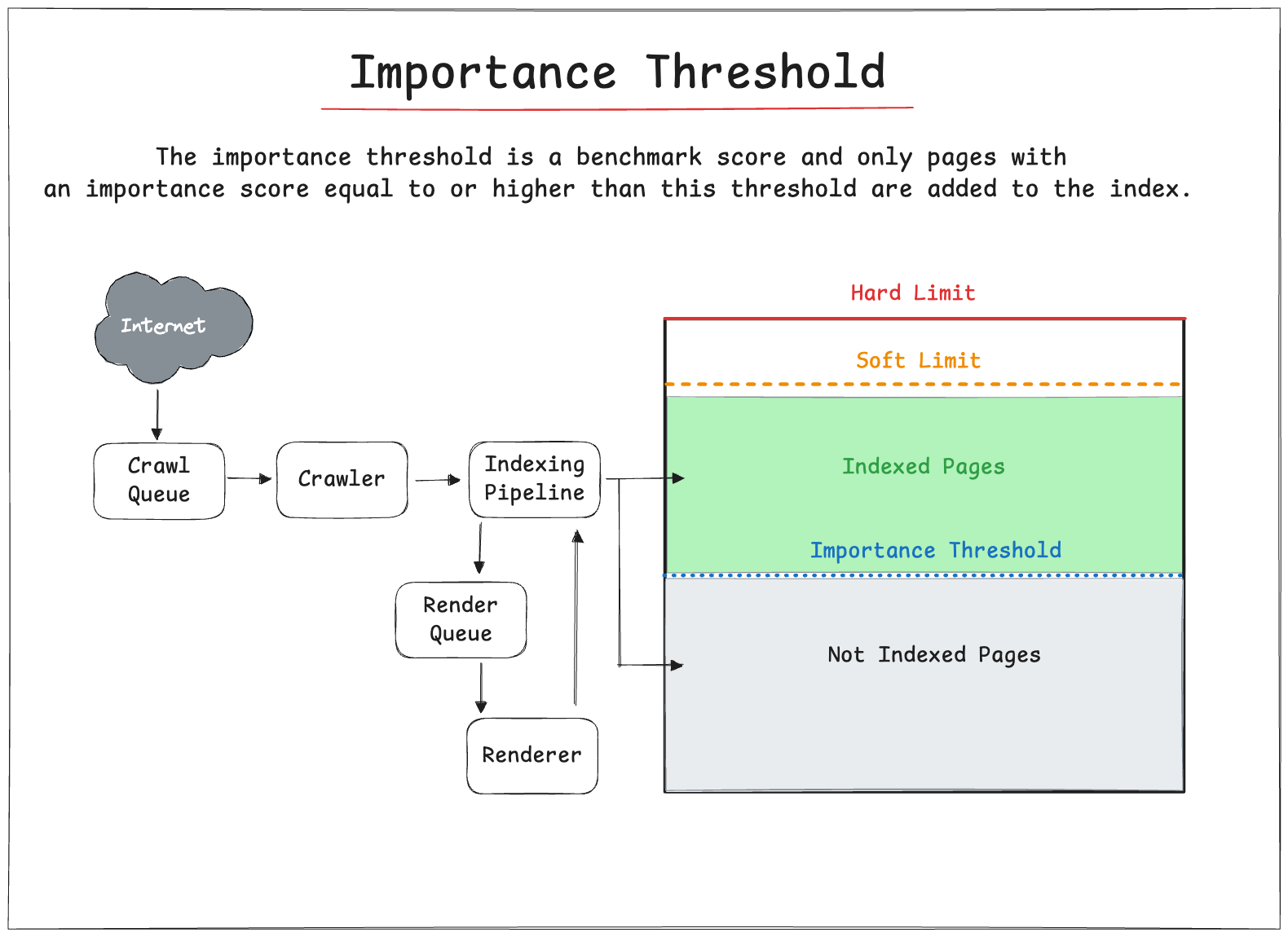
This ensures that a search engine index prioritizes indexing the most important content.
Based on the patent, there are two main methods for determining the importance threshold:
🔢 Ranking Comparison Method
🏛️ Histogram-Based Method
🔢 Ranking Comparison Method
All known pages are ranked according to their importance.
The threshold is implicitly defined by the importance rank of the lowest-ranking page currently in the index.
For example, if a search engine had 1,000,000 pages indexed. It would rank (sort) the pages based on each calculated importance score. The lowest importance rank the list would be 3.
So the importance threshold in the Search Index would be 3.
🏛️ Histogram-Based Method
The system would use a histogram representing the distribution of importance ranks.
The threshold is calculated by analyzing the histogram and identifying the importance rank corresponding to the desired index size limit.
For example, if a search engine had a limit of 1,000,000 pages. If the histogram shows that 800,000 pages have an importance rank of 6 or higher, the importance threshold would be 6.
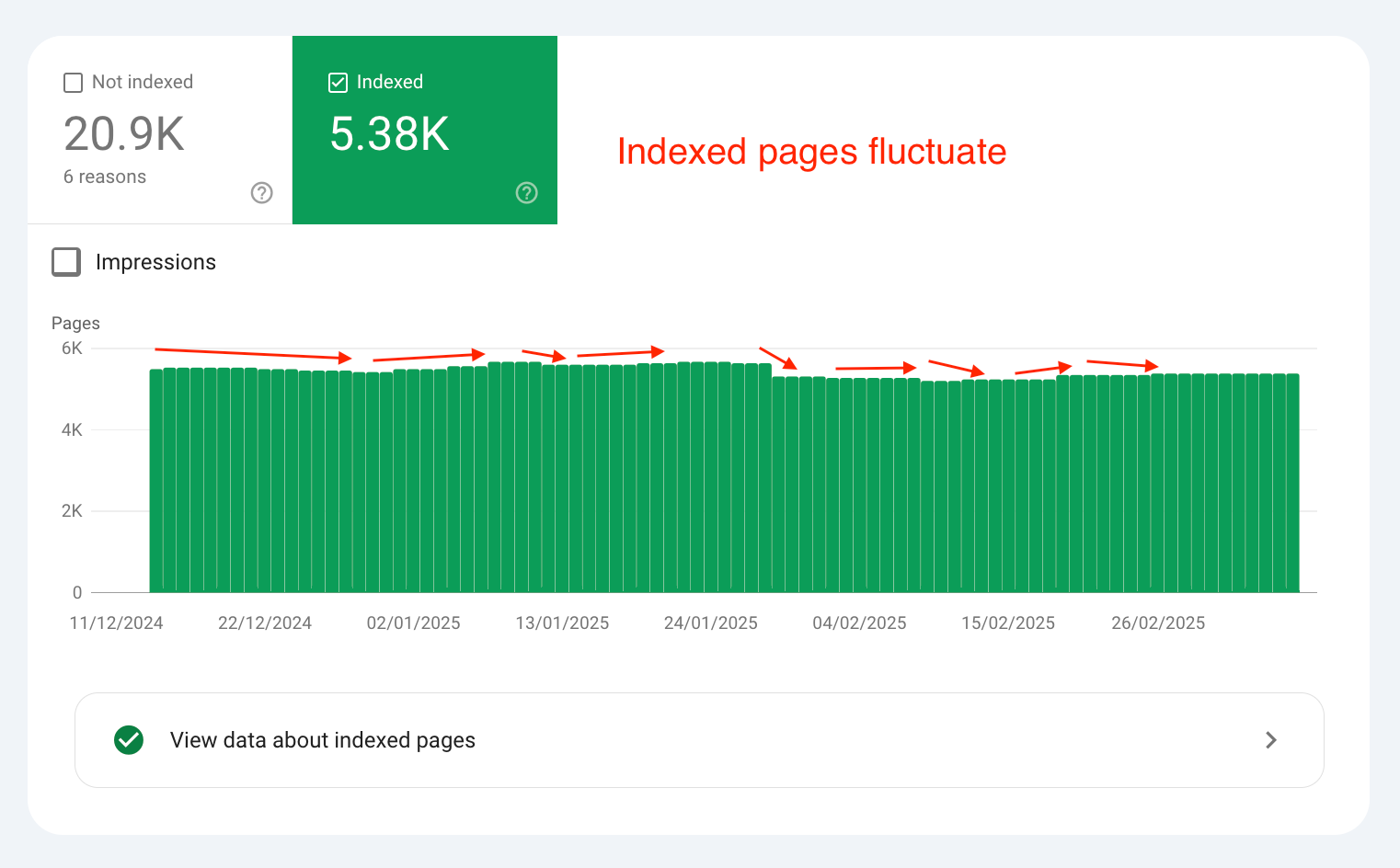
📊 Importance threshold fluctuates
The number of indexed pages can fluctuate due to the importance threshold.
This is due to the dynamic nature of both the importance threshold and the importance rankings of individual pages.
You can see this sort of process in action in the Page Indexing report in GSC.
According to the patent, three main factors cause these fluctuations:
🆕 New High-Importance Pages
🚨 Oscillations Near Threshold
📊 Importance Rank Changes
🆕 New High-Importance Pages
When new pages with importance rank above the current threshold, they're added to the index.
This can cause the total number of pages to exceed the soft limit, triggering an increase in the importance threshold and potentially removing existing pages with lower importance.
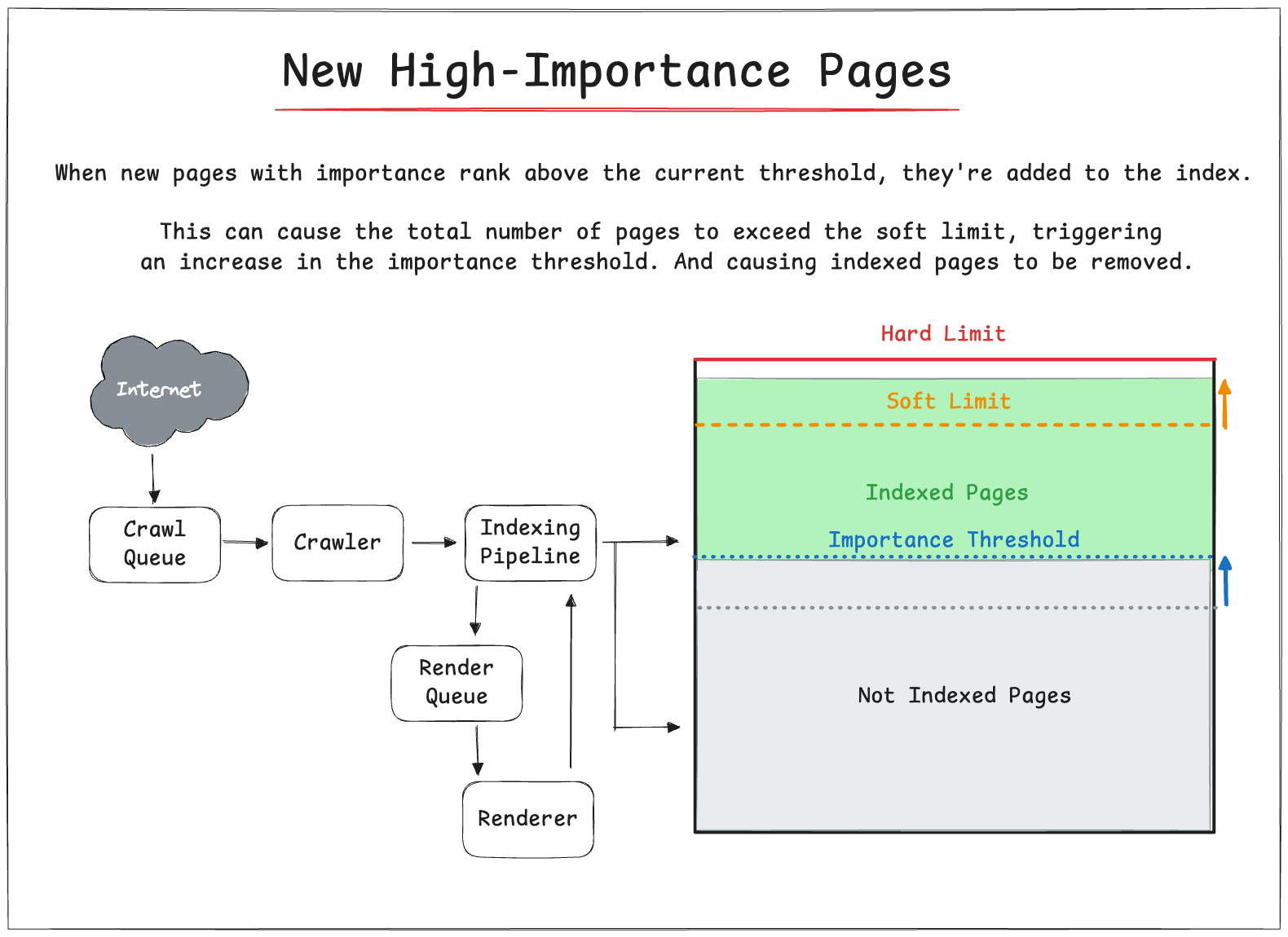
Gary Illyes actually confirmed that this process happens in Google’s Search Index.
Poor quality content (lower importance rank) will be actively removed if higher quality content is needs to be added to the index.
🚨 Importance Rank Changes
Existing pages are removed from the index because they drop below the unimportance threshold.
If an existing page's importance rank drops below the unimportance threshold (due to content updates, link structure changes, or poor user engagement from session logs), it might be deleted from the index, even if it was previously above the importance threshold.
Indexing Insight first-party data has seen indexed pages become not indexed pages in our ‘Crawled - previously indexed’ report.
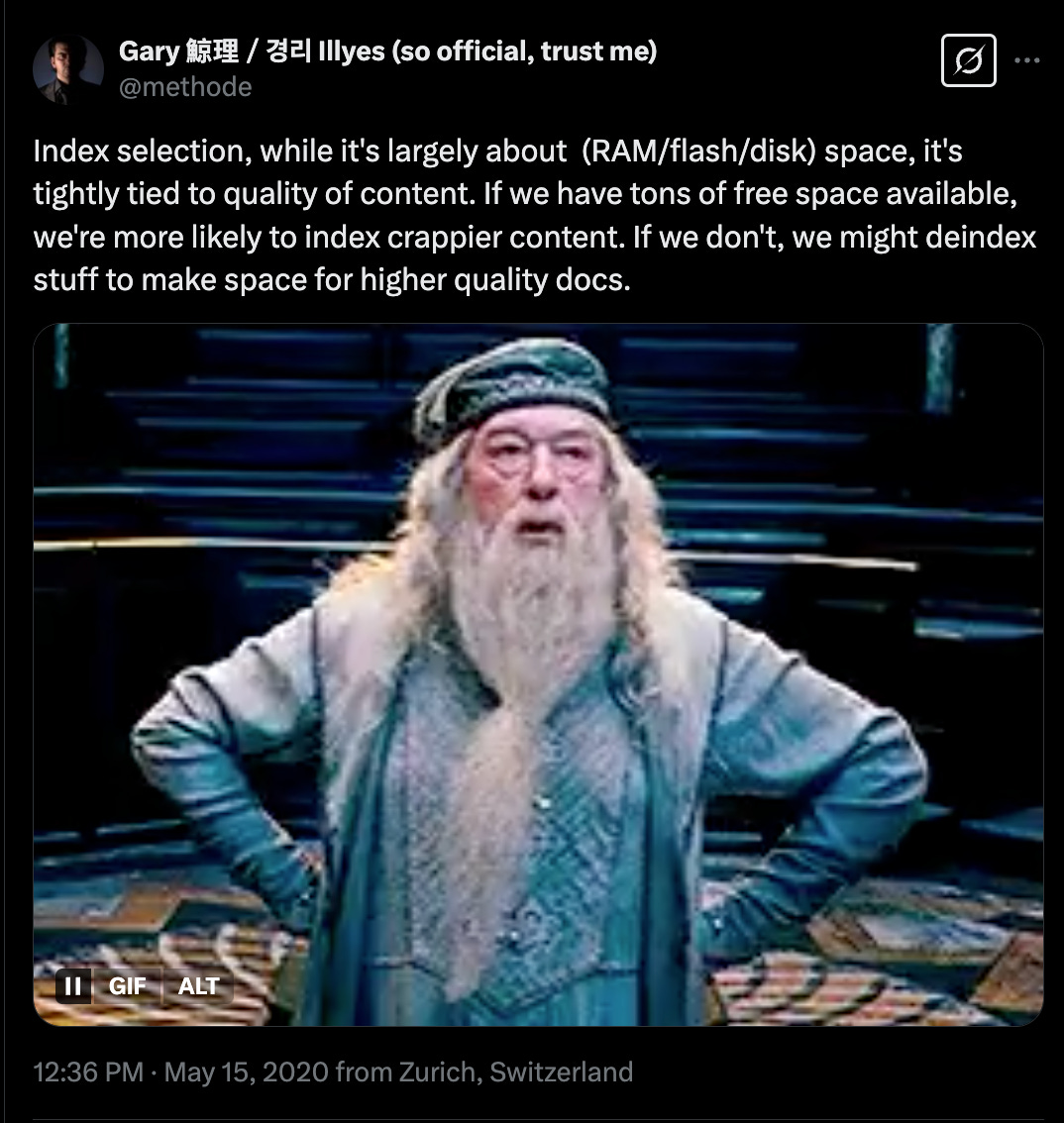
Gary Illyes confirmed that Google Search’s index tracks signals over time and that these can be used to decide to remove pages from its search results:
“And in general, also the the general quality of the site, that can matter a lot of how many of these crawled but not indexed, you see in Search Console. If the number of these URLs is very high that could hint at a general quality issues. And I've seen that a lot uh since February, where suddenly we just decided that we are de-indexing a vast amount of URLs on a site just because the perception, or our perception of the site has changed.”
- Gary Illyes, Google Search Confirms Deindexing Vast Amounts Of URLs In February 2024
📊 Oscillations Near Threshold
Pages with importance ranks close to the threshold are particularly susceptible to fluctuations.
As the threshold and importance ranks dynamically adjust, these pages might be repeatedly crawled, added to the index, and then deleted.
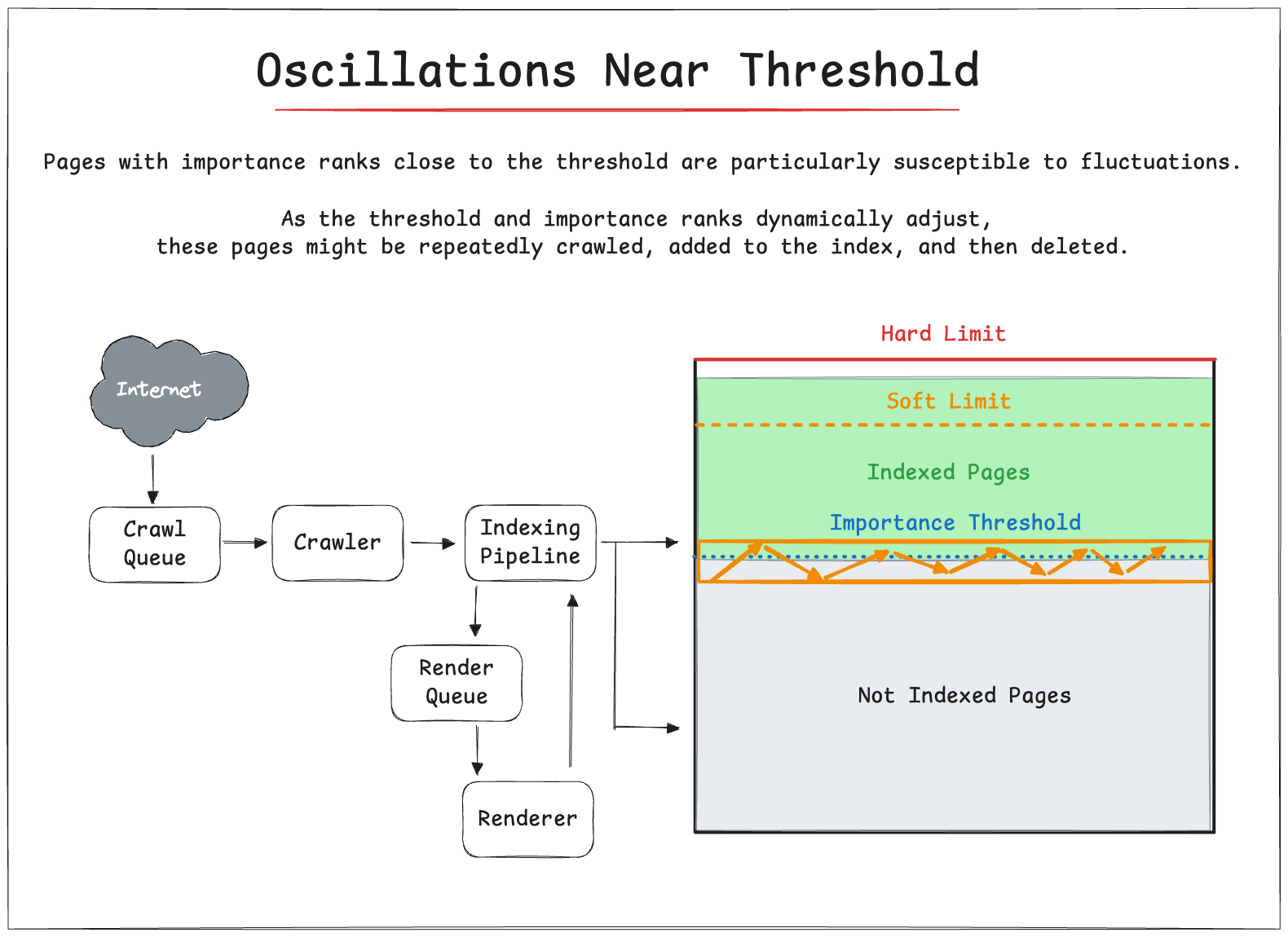
This creates oscillations in the index size.
The patent describes using a buffer zone to mitigate these oscillations, setting the unimportance threshold slightly lower than the importance threshold for crawling.
This reduces the likelihood of repeatedly crawling and deleting pages near the threshold.
Gary Illyes again confirms that a similar system happens in Google’s Search Index, indicating that pages very close to the quality threshold can fall out of the index.
But it can then be crawled and indexed again (and then fall back out of the index).
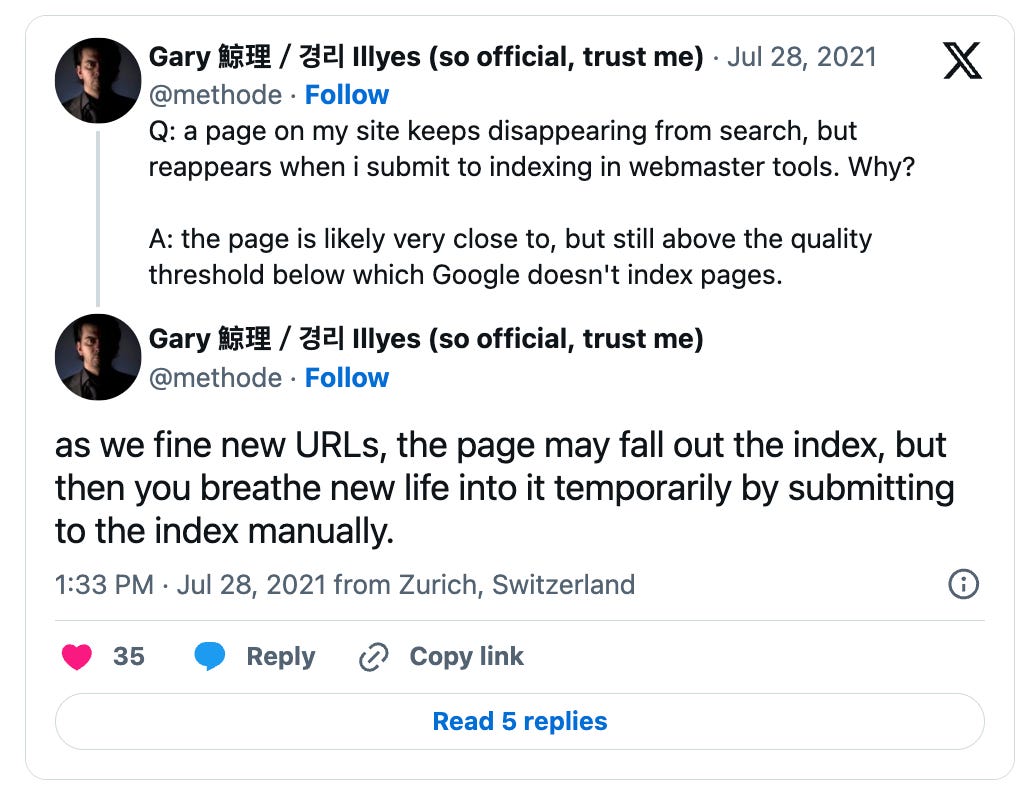
Indexing states: Why do they change?
The patent also explains why your page’s indexing states can change over time.
At Indexing Insight, we have noticed using our first-party data that indexing state in GSC can indicate the crawl priority of a website.
The Google patent (US7509315B1) explains why this happens using two systems:
🔄 Soft vs Hard Limits
🚦 Importance threshold and crawl priority
🔄 Soft vs Hard Limits
There are two different limits to managing a search engine’s index effectively:
Soft Limit: This limit sets a target for the number of pages to be indexed.
Hard Limit: This limit acts as a ceiling to prevent the index from growing excessively large.
These two limits work together to ensure Google's index remains manageable while prioritizing high-ranking documents.
For example, if Google’s Search Index has a soft limit of 1,000,000 URLs, and the system detects they have hit that target, then Google will start to increase the importance threshold.
The result of increasing the importance threshold removes indexed pages that are below the importance threshold.
Which impacts the crawling and indexing of new pages.
🚦 Importance threshold and crawl priority
The importance threshold directly influences which URLs get crawled and indexed.
Here's how it works according to the patent when the soft limit is reached:
Only pages with an importance rank equal to or greater than the current threshold are crawled and indexed.
As the threshold dynamically adjusts, URLs' crawl and indexing priority changes.
URLs with an importance rank far below the threshold have zero crawl priority.
This system explains why some pages move from the "Crawled—currently not indexed" to the "URL is Unknown to Google" indexing states in Google Search Console.
It's all about their importance rank relative to the current threshold.
The decline in importance rank score over time means that a URL can go from:
⚠️ “Crawled—currently not indexed"
🚧 “Discovered —currently not indexed"
❌ "URL is Unknown to Google"
Gary Illyes from Google confirmed that Google’s Search Index does “forget” URLs over time based on the signals. And that these URLs have zero crawl priority.

🤓 What does this mean for you (as an SEO)?
Understanding Google's index management can directly impact your SEO success.
Here are 4 tips to action the information in this article:
🚑 Monitor your indexing states
🏆 Focus on quality over quantity
🧐 Identify content that's at risk
🔄 Regularly audit and improve existing content
🚑 Monitor your indexing states
Check your indexing states on a weekly or monthly basis, especially after core updates.
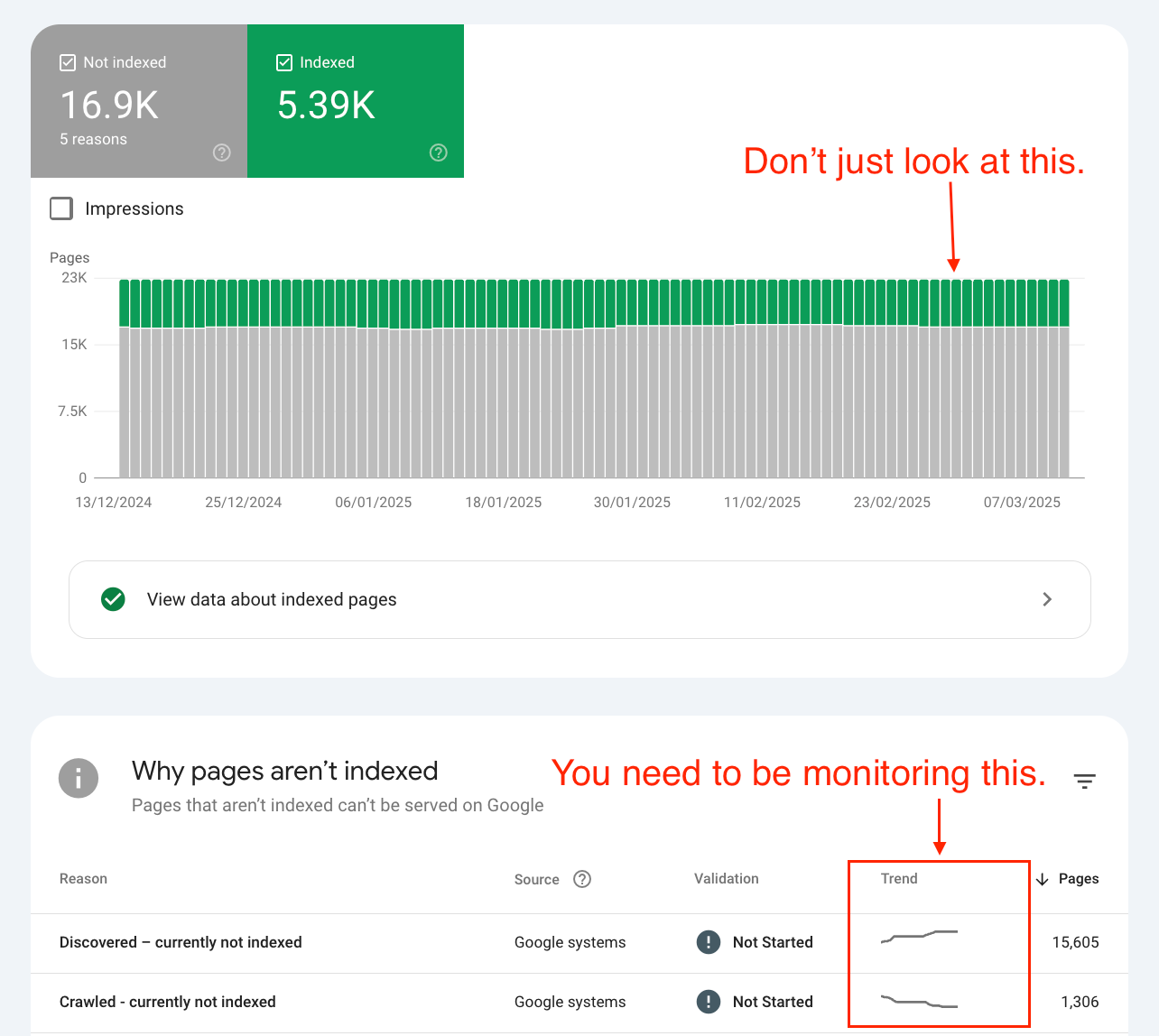
Pay attention to the following trends:
Increase in pages in the 'Crawled - currently not indexed' report
Increases in pages in the 'Discovered - currently not indexed' report
Pages that are being flagged as 'URL is unknown to Google' in GSC
These shifts can indicate that Google is actively deprioritizing or removing your content from the index based on importance thresholds.
🙋♂️ Note to readers
Google Search Console makes monitoring indexing states difficult.
You can read more about why here:
🏆 Focus on content quality over quantity
The importance threshold mechanism shows that Google constantly evaluates page quality relative to the entire web.
This means:
Higher-quality pages push out lower-quality pages from the index
Importance score of your pages continues to worsen if you don’t improve them
Your content isn't just competing against your previous versions but against all new content being created.
This explains why a page that was indexed for years can suddenly get deindexed. Its importance rank may have remained static while the threshold increased.
🧐 Identify content that's at risk
URLs with frequent indexing state changes (oscillating between indexed and not indexed) are likely near the importance threshold.
These pages should be prioritized to be improved.
For example, if you notice a page was previously indexed but now shows as 'Crawled - currently not indexed', it's likely hovering near the importance threshold.
🔄 Regularly audit and improve existing content
The patent suggests that Google continually reassesses page importance.
To maintain and improve your indexing, it’s important to:
Perform regular content audits focusing on thin content
Update and improve existing content rather than just creating new pages
Monitor internal links and user engagement metrics as they influence importance.
📌 Summary
Google actively removes pages from its index.
In this newsletter, I explained how Google MIGHT use a set of processes to help manage its Search Index using the Google patent (US7509315B1).
The patent sheds some light on how your pages can be actively removed.
The concepts in the patent help explain indexing behaviour they are witnessed by SEO professionals when they use Google Search Console.
Hopefully, this newsletter has given you a deeper understanding of how Google works and what you should be doing to help get your pages indexed.