


New Study: After 190 Days Since Last Crawl Googlebot Forgets
A new study from Indexing Insight reveals that if a page is not recrawled within 190 days then it is actively forgotten and has zero crawl priority.

Subscribe to the newsletter to get more unique indexing insight straight to your inbox…
…or watch a demo of Indexing Insight which helps large-scale sites diagnose indexing issues.
At Indexing Insight, a study has uncovered a 190-Day Not Indexed rule.
After 190 days since last crawl, Googlebot "forgets" a Not Indexed page even exists. This rule is based on a study of 1.4 million pages across 18 different websites (see methodology for more details).
Our study focused on combing the Days Since Last Crawl (based on Last Crawl Time) and the index coverage states from the URL Inspection API.
In this newsletter, I'll explain the 190-day rule for page forgetting and how it affects your SEO strategy.
Let's dive in.
💽 Methodology
The indexing data pulled in this study is from Indexing Insight. Here are a few more things to keep in mind when looking at the results:
👥 Small study: The study is based on 18 websites that use Indexing Insight of various sizes, industry types and brand authority.
⛰️ 1.4 million pages monitored: The total number of pages used in this study is 1.4 million and aggregated into categories and analysed to identify trends.
🤑 Important pages: The websites using our tool are not always monitoring ALL their pages, but they monitor the most important traffic and revenue-driving pages.
📍 Submitted via XML sitemaps: The important pages are submitted to our tool via XML sitemaps and monitored daily.
🔎 URL Inspection API: The Days Since Last Crawl metric is calculated using the Last Crawl Time metric for each page is pulled using the URL Inspection API.
🗓️ Data pulled at the end of March: The indexing states for all pages were pulled on 6/05/2025.
Only pages with last crawl time included: This study has included only pages that have a last crawl time from the URL Inspection API for both indexed or not indexed pages.
Quality type of indexing states: The data has been filtered to only look at the following quality indexing state types: ‘Submitted and indexed’, ‘Crawled - currently not indexed’, ‘Discovered - currently not indexed’ and ‘URL is unknown to Google’. We’ve filtered out any technical or duplication indexing errors.
🕵️ Findings
Googlebot forgets or has forgotten pages that have not been crawled in 190 days.
Our data from 1.4 million pages across multiple websites shows that if a page has not been crawled in 190+ days then there is a 90% chance the page will be either start to be forgetten or forgotten by Google Search.
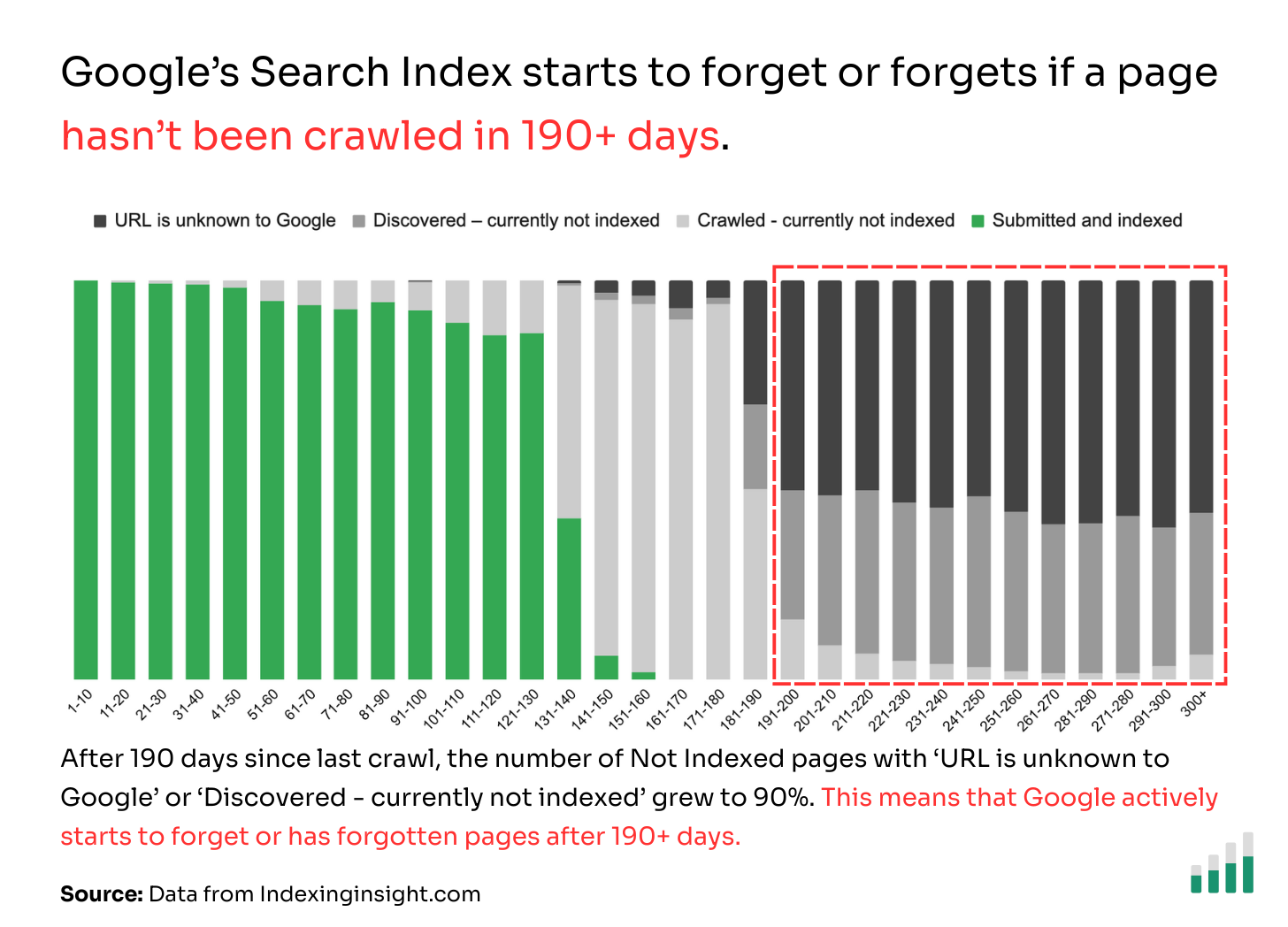
Below is the raw data to understand the scale of the pages in each category.

How did we come to this conclusion when looking at this data?
Over the last 12 months while building the tool we’ve noticed that three indexing states (‘Crawled - currently not indexed’, ‘discovered - currently not indexed’, and ‘URL is unknown to Google’) changed based on the URL's crawl priority.

Our research highlighted that the definition of these 3 not indexed coverage states in Google Search Console needs to change:
Crawled - currently not indexed: The page has either been discovered, crawled but not indexed OR the historically indexed page has been actively removed from Google’s search results.
Discovered—currently not indexed: A new page has been discovered but not yet crawled, OR Google is actively forgetting the historically indexed page.
URL is unknown to Google: A page has never been seen by Google OR Google has actively forgotten the historically crawled and indexed pages.
Note: You can read more about our research and data here:
After seeing this trend multiple times across different customer sites, we did some research into Google’s Search index to understand why this happened.
Based on our research we found that Google’s Search index is designed to actively remove pages from its search results AND forget about them over time.
Note: You can read more about our research and data here:
To quickly summarise the research:
The 3 not indexed coverage states you see in Google Search Console (‘Crawled - currently not indexed’, ‘Discovered - currently not indexed’, and ‘URL is unknown to Google) reflect the crawl priority of those pages.

As a page becomes forgotten it moves through these 3 not indexed coverage states. Eventually reaching the ‘URL is unknown to Google’.
This research was supported by a comment from Gary Illyes when asked on LinkedIn why historically crawled and indexed pages can move to ‘URL is unknown to Google’:
“Those have no priority (URL is known to Google); they are not known to Google (Search) so inherently they have no priority whatsoever. URLs move between states as we collect signals for them, and in this particular case the signals told a story that made our systems "forget" that URL exists. I guess you could say it actually fell out the barrel altogether.”
The reply here mentions that URLs move between “states” as Google’s system picked up signals over time (which backs up our own research). And that historically crawled and indexed pages can eventually move to ‘URL is unknown to Google’.
To quote Gary, Google’s systems will eventually “forget” that a URL exists.
The data from Indexing Insight gives us the ability to measure and monitor how long it takes for Google to ‘forget’ a URL. All by using the Last Crawl Time metric.

If we combine the data from the 130-day indexing rule study we can build a picture of how long it takes for a page to be forgotten by Google’s Search index:
✅ 1-130 days: Between 1 - 130 days of being crawled 90% of the pages are ‘submitted and indexed’.
❌ 131-180 days: Between 131 - 190 days 50% - 90% of the not indexed pages have ‘crawled - currently not indexed’ index coverage state.
👻 190+ days: After 190 days since the pages were crawled 90% of the pages are made up of ‘Discovered - crawled currently not indexed’ or ‘URL is unknown to Google’.
If we layer this data over how Google’s Search index (might) work diagram we can now fill in the gaps for the different crawl priority “tiers”.
After a page has been deindexed it doesn’t take long for it to be “forgotten” by Google (zero priority) in the crawling queue.
After just 60 days of not being crawled a page can go from ‘Crawled - currently not indexed’ to ‘Discovered - currently not indexed’ or ‘URL is unknown to Google’.
It can take 4 months for Google to actively remove a page from search results (indexed to not indexed) but only 2 months for not indexed pages to start to be forgotten by Google (meaning zero or close to zero crawling priority).

🧠 Final Thoughts
SEO teams can make educated guesses on crawl frequency reflecting how important a page is to Google but our study (and research) should remove a lot of guesswork.
Now we have a clear set of benchmarks that we can use to inform our SEO strategies.
For example, when using URL Inspection API with Screaming Frog you can now start to understand the crawl priority of your indexed and not indexed pages.

By understanding the crawl priority of your pages using index coverage states you can also start to uncover quality issues on your website. AND start to identify which indexed pages are at risk of being deindexed.

At Indexing Insight we’re working hard in the background to group pages into Days Since Last Crawl reports to help customers identify unique SEO insights that can help inform content quality.

Do you want to monitor Google indexing and crawling at scale?
Indexing Insight is a Google indexing intelligence tool for SEO teams who want to identify, prioritise and fix indexing issues at scale.
Watch a demo of the tool below to learn more 👇.